7.Redis 主从复制
7.1 Redis 主从复制的基本概念
- 主节点(Master)与从节点(Replica)
- 在 Redis 术语中,传统称呼是 Master 和 Slave,从 5.0 开始社区倾向使用 Master 和 Replica 来替代。
- Master 负责处理写请求,并将写操作同步到 Replica;Replica 负责接收 Master 同步过来的数据,并对外提供读服务(如果配置了
replica-read-only no,也可以写,但通常不建议这样做)。
- 异步复制(Asynchronous Replication)
- Redis 的主从复制本质上是 异步复制,即 Master 在将写操作返回给客户端后,会在后台将数据同步给 Replica。
- 对于强一致性要求较高的场景,需要做额外的配置或处理(如 Wait、min-replicas-to-write 等机制)。
- Sentinel 与 Cluster 模式
- Sentinel 是 Redis 提供的自动故障检测与主从切换的工具,通过监听主节点的健康度,来进行自动化的故障转移。
- Cluster 模式则是 Redis 官方推荐的多节点分片方案,同样具备部分自动的故障转移能力,且更适合于分布式水平扩展的场景。
- 无论使用 Sentinel 还是 Cluster,本质上都基于主从(主备)复制来实现高可用。
7.2 Redis 主从复制的工作流程
要理解 Redis 7.4 的复制特性,我们先回顾一下 Redis 在 2.8 之后引入的 PSYNC(部分重同步) 机制,以及 6.x、7.x 中的改进。它们在底层架构上没有根本性变化,但对复制的稳定性、内存使用和网络消耗做了优化。
- 初次全量复制(Full Synchronization)
- 当 Replica 节点第一次向 Master 发起复制请求,或者复制状态失效(无法进行部分重同步)时,会触发一次 “全量复制”。
- Master 会执行以下操作:
- 触发保存 RDB 文件(或者使用已有的 RDB 文件)
- 通过网络将 RDB 文件发送给 Replica
- 在 RDB 文件发送完毕后,会将积累的增量命令(AOF 或命令缓存)发送给 Replica
- Replica 在收到 RDB 后会先将其加载到内存,再应用后续增量命令,直到与 Master 同步到相同的 offset(复制偏移量)。
- 部分重同步(Partial Resynchronization)
- 如果 Replica 与 Master 断开连接(网络故障、超时等)后重新连接,Replica 会把自己保存的 Replication Offset(复制偏移量)和 Replication ID(同步 ID)发送给 Master。
- 如果 Master 还能在复制积压缓冲区(Replication Backlog)中找到从 Replica 上次断开后遗漏的那部分数据,就可以直接进行 “部分重同步”,只发送缺失的命令给 Replica,避免重复执行一次全量数据同步,从而减少网络和 IO 开销。
- 复制偏移量(Replication Offset)与复制缓冲区(Replication Backlog)
- Master 在处理命令时,会维护一个全局增长的 offset,同时把最近一段时间的写命令缓存到 Backlog。
- 当 Replica 发起 PSYNC 请求时,会带上自己的 offset 和上一次复制的 Master Replid,Master 检查是否能满足部分重同步,否则只能再次进行全量复制。
- 主从复制的异步特性
- Redis 复制是 异步 的,Master 在写操作完成后就返回给客户端,后台才向 Replica 发送复制数据。
- 如果需要保障数据安全(例如避免主节点宕机时数据丢失过多),需要配合
min-replicas-to-write、min-replicas-max-lag等配置项来做一定程度的同步保障。
7.3 配置与运维要点
7.3.1 基本配置
在 redis.conf 或者使用 CONFIG SET 命令,可以进行以下配置来启用和管理复制功能:
- Master 侧配置
一般情况下,主节点不需要额外做什么特殊配置,只要正常提供服务即可。
如果你为 Master 设置了访问密码(例如 requirepass),你需要在 Slave 端做相应的身份认证配置。
-
Slave 侧配置
replicaofreplicaof 10.0.0.42 6379 或在 Redis 运行中执行:
REPLICAOF -
密码相关
- 如果 Master 设置了访问密码,需要在 Replica 配置:
masterauthmasterauth 123456 - Replica 自身的
requirepass用于客户端访问 Replica 时的密码,与复制用的masterauth并不相同。
-
只读模式
- Redis 默认开启
replica-read-only yes,从节点只接受读请求,不允许外部写,从而避免写入冲突。
- Redis 默认开启
-
延迟优化
repl-disable-tcp-nodelay、client-output-buffer-limit以及网络相关参数可视业务场景进行调优。
# 通过命令行直接设置(Redis的版本要保持一致,如果不一致可能会无法复制)
# 所有从节点执行
127.0.0.1:6379> REPLICAOF 10.0.0.42 6379
127.0.0.1:6379> CONFIG SET masterauth 123456
# slave1 从节点状态
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:10.0.0.42
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_read_repl_offset:64185
slave_repl_offset:64185
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8ba3aa667f0d3e54f4c6499d4d42ce0f68ccce8f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:64185
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:962
repl_backlog_histlen:63224
127.0.0.1:6379>
# slave2 从节点状态
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:10.0.0.42
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_read_repl_offset:2109
slave_repl_offset:2109
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8ba3aa667f0d3e54f4c6499d4d42ce0f68ccce8f <-- 主节点的 replid
master_replid2:0000000000000000000000000000000000000000 <-- 备用 replid
master_repl_offset:2109
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:738
repl_backlog_histlen:1372
127.0.0.1:6379>
# 主节点状态
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=10.0.0.40,port=6379,state=online,offset=1045,lag=0
slave1:ip=10.0.0.41,port=6379,state=online,offset=1045,lag=0
master_failover_state:no-failover
master_replid:8ba3aa667f0d3e54f4c6499d4d42ce0f68ccce8f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1045
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:6
repl_backlog_histlen:1040
127.0.0.1:6379>role:slave:本实例是从节点。
master_link_status:up:当前和主节点连接正常。
master_last_io_seconds_ago:8:上一次从主节点收到数据到现在,已经过了 8 秒。
master_sync_in_progress:0:表示目前没有在做全量复制或同步过程;如果在进行全量同步,会显示 1。
slave_read_repl_offset、slave_repl_offset:该从节点当前已读取/执行到的复制偏移量。
master_replid:主节点的复制 ID。
master_replid2:备用 ID,默认是全 0,如果没有经历故障转移或者没有开启相关功能,通常不会被使用。
master_repl_offset:主节点上的全局复制偏移量。
**replbacklog***:与复制积压缓冲区的状态相关。
connected_slaves:0:因为这是一个从节点,不会再带其他从节点,所以其下级从节点数量是 0。
7.3.2 宕机与故障恢复
- 断电 / 宕机后再次启动
- 如果 Replica 的偏移量信息仍然保留,且 Master 的 backlog 中还包含所需的增量数据,则会触发 部分重同步;否则进行 全量同步。
- 需要重点关注磁盘剩余空间、内存容量以及网络带宽,避免在高并发或超大 RDB 传输时给系统带来风险。
- 监控与告警
- 建议通过
INFO replication监控以下指标: role:节点角色(master / replica)connected_slaves:当前连接的从节点数量repl_backlog_active、repl_backlog_size和 backlog 的使用情况master_link_status:从节点与主节点的连接状态(up / down)master_sync_in_progress:从节点是否在进行同步- 结合其他监控系统(如 Prometheus + Grafana)将复制状态可视化,便于及时发现问题。
- 建议通过
- 手动故障转移
- 如果使用 Sentinel,可以在主节点故障时自动提升某个从节点为新主节点。
- 如果没有使用 Sentinel 或集群,需要手动执行
REPLICAOF NO ONE将某个从节点晋升为主节点,并重新配置其他节点的复制指向。
7.3.3 性能调优
- 减小全量复制的概率
- 适度增大
repl-backlog-size,让主节点可以保存更多增量命令,减少重连后出现 “无法部分重同步” 的情况。 - 优化网络状况,缩短复制延迟,降低 Replica 失联几率。
- 适度增大
- 合理使用磁盘复制(Diskless Replication)
- 若磁盘 IO 压力较大或者环境允许,可以打开
repl-diskless-sync yes。 - 在大规模场景下需要评估内存峰值,避免产生过大的内存消耗导致 OOM。
- 若磁盘 IO 压力较大或者环境允许,可以打开
- 多副本策略
- 如果业务有严格的数据安全需求,可以多实例部署,从节点数量增加后,通过
min-replicas-to-write和min-replicas-max-lag机制做一定程度的 “半同步”(写安全)保护。 - 但要注意过多 Replica 也会加大主节点带宽压力和内存开销。
- 如果业务有严格的数据安全需求,可以多实例部署,从节点数量增加后,通过
7.4 主从复制故障恢复
如何在 Redis 中手动配置 主从复制(Master-Replica) 以及在 Master 节点故障后如何手动将 Slave(Replica) 提升为新的主节点的整个过程。
- 纯手动配置
- 基于 Sentinel 的自动/半自动故障转移。
Master 节点故障 & 手动提升 Slave
当 Master 节点 “挂了” 或出现严重故障,需要将 Slave 节点变成新的 Master,这个过程称为 故障转移 或 主从切换。
- 确定 Master 已不可用
- 通过监控、日志或运维工具确认 Master 节点宕机,或者无法在短时间内修复。
- 在 Slave 上停止复制,提升为主
- 登录到 Slave 节点:
redis-cli -h 10.0.0.40 -p 6379- 执行:
REPLICAOF NO ONE此命令会让当前节点放弃做从节点的角色,成为一个“独立”的主节点,今后写入将直接在这个节点生效。
- (可选)如果原本 Master 设置了密码,而当前节点也需要对客户端进行认证,可在
redis.conf中设置requirepass new-password,或者用CONFIG SET requirepass new-password。
- 检查新的 Master 状态
- 再次执行
INFO replication,应当看到role: master,且connected_slaves: 0。 - 测试写入:
SET new_test_key "i_am_new_master"
GET new_test_key如果返回正确,说明新的 Master 工作正常
- 其他节点(如果有多个)重新指向新的 Master
- 如果原来还有其他从节点,需要将它们也切换到指向新的 Master:
redis-cli -h <other-slave-ip> -p 6379 REPLICAOF 10.0.0.40 6379- 如果之前没有设置 Sentinel 或自动化脚本,需要一台台手动执行。
使用 Sentinel 自动化或半自动化故障转移
如果你觉得 纯手动 的方式在生产环境不够及时或存在人工失误的风险,Redis 提供了 Sentinel 组件,能够实现自动或半自动的故障检测与主从切换。
1. Sentinel 的工作原理简述
- Sentinel 进程会不断地监控主服务器和从服务器的健康状态。
- 当 Sentinel 认为主服务器处于宕机状态(经过若干次判断确认),它会在剩余的 Sentinel 进程间通过投票确定是否真的故障。
- 一旦确认 Master 故障,Sentinel 会将某一台 Slave(Replica)提升为新的 Master,并向其他从节点发布更新,指向新的 Master。
- 客户端可以通过 Sentinel 获取最新的 Master 信息,从而始终向正确的主节点发送写请求。
2. Sentinel 配置示例
假设有三台机器部署了三个 Sentinel 实例(一般生产环境要有奇数个 Sentinel,至少 3 个)。这里简单示范一个 Sentinel 的配置文件(sentinel.conf)核心片段:
port 26379
# 监控指定Master:<MasterName> <ip> <port> <quorum>
# quorum 是判断宕机所需要的最少 Sentinel 同意票数
sentinel monitor mymaster 192.168.1.10 6379 2
# 如果 Master 设置了密码,请使用:
sentinel auth-pass mymaster <master-password>
# 故障转移时新 Master 的复制配置
sentinel config-epoch mymaster 0
# 开启通知脚本(可选),当故障转移时执行某些通知动作
# sentinel notification-script mymaster /var/redis/scripts/notify.sh
# 故障转移后执行的脚本(可选),比如更改应用配置
# sentinel reconfig-script mymaster /var/redis/scripts/reconfig.sh
# 指定检测 Master、Slave、Sentinel 的周期、超时时间等
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
- 启动 Sentinel:
redis-sentinel /path/to/sentinel.conf-
通过
redis-cli -p 26379 SENTINEL masters、SENTINEL slaves mymaster可以查看当前 Sentinel 监控到的主从信息。 -
一旦主节点故障,Sentinel 会经过判定和投票,将一个 Slave 自动提升为 Master 并更新集群拓扑
提示:如果希望在故障时人工确认后再切换,也可以结合脚本,让 Sentinel 先发出通知,运维手动执行
SENTINEL failover mymaster命令触发故障转移,这就变成了“半自动化”方案。
在 Redis 的主从复制机制中,主要存在两种数据同步方式:全量复制(Full Resynchronization)\和**增量复制(Partial Resynchronization)**。下面从原理和流程两方面进行介绍。
7.5 全量复制(Full Resynchronization)
当从节点(Slave)第一次连接到主节点(Master),或者因网络抖动、断线导致主从复制状态不一致且无法通过增量复制来追赶时,就需要执行全量复制。
1. 触发条件
- 从节点首次连接主节点:新的从节点刚刚启动或没有复制状态,需要获取主节点的全部数据。
- 断线后 backlog 不足:如果从节点断线时间较久,主节点的复制积压缓冲区(replication backlog)已经覆盖了所需的数据增量,无法完成增量复制,就会触发全量复制。
2. 流程概述
- 从节点向主节点发送
PSYNC命令- 当从节点第一次连接主节点或者复制信息不一致时,会发送形如
PSYNC ? -1的命令,表示需要进行全量复制。 - 如果主节点发现这是一个无法进行部分复制的请求(要么是第一次连接,要么 backlog 中无对应 offset),则返回
FULLRESYNC <runid> <offset>,表示将进入全量复制过程。
- 当从节点第一次连接主节点或者复制信息不一致时,会发送形如
- 主节点执行快照(RDB)并发送给从节点
- 主节点接收到从节点的全量复制请求后,会
fork()出一个子进程执行BGSAVE,生成一份 RDB 快照文件。 - 在生成 RDB 的过程中,主节点会将新写入操作(增量数据)放入一个缓冲区(复制缓冲 buffer)中。
- RDB 文件准备好后,主节点会通过套接字把 RDB 文件发送给从节点。
- 主节点接收到从节点的全量复制请求后,会
- 从节点加载 RDB
- 从节点接收到 RDB 文件后,会先清空现有数据,再将 RDB 文件中的数据加载到内存,完成数据的“快照恢复”。
- 传输增量指令
- 当从节点完成 RDB 加载后,主节点会将全量复制期间缓冲的写操作(AOF 同步流或复制缓冲区)一并发送给从节点,从节点会依次执行这些命令,以使数据最终与主节点保持同步。
- 切换到命令持续复制
- 全量复制完成后,从节点会正式进入主从复制状态,此后主节点会将后续的写命令以“命令流”的形式持续发给从节点,从节点实时执行,实现最终一致。
7.6 增量复制(Partial Resynchronization)
增量复制也称为部分重同步,当从节点与主节点之间出现短暂断线或从节点本身保持了“复制偏移量”并且主节点保存了足够的“复制积压缓冲区”(replication backlog)时,就能通过增量复制快速“追上”主节点的写操作。
1. 基本概念
- runid:每个 Redis 实例都有一个唯一运行 ID,用于在从节点追踪主节点身份时识别主节点。
- 复制偏移量(offset):主节点给自己的每条写命令分配一个递增的 offset,从节点通过上报自身已复制的 offset 来确定需要补齐的数据量。
- 复制积压缓冲区(replication backlog):主节点中用环形缓冲区存储最近一段时间的写操作(命令流),以便断线的从节点在恢复连接后,可以从 backlog 补齐这段期间内缺失的指令,而无需执行全量复制。
2. 流程概述
- 从节点向主节点发送
PSYNC <master_runid> <offset>- 从节点在断线重连后,会携带上一次记录的主节点 runid 和复制 offset,向主节点请求进行部分复制。
- 主节点检查复制 backlog
- 主节点对比从节点发来的 offset 与自身维护的 backlog:
- 如果 offset 在 backlog 的可用范围内(即主节点仍然保留了这部分写命令),则可以进行部分复制。
- 如果 offset 不在 backlog 范围内(丢失了更多数据或主节点 runid 发生变化),则需要转为全量复制。
- 主节点对比从节点发来的 offset 与自身维护的 backlog:
- 执行增量复制
- 如果符合条件,主节点会从 backlog 中取出从节点所缺失的写命令,依次发送给从节点。
- 从节点依次执行这些指令,完成数据追赶。
- 持续复制
- 当 backlog 的数据补齐后,从节点就和主节点重新保持一致,进入正常的命令流复制阶段。
3. 全量复制与增量复制的联系
- 全量复制是一个“重置性”的过程,通常会带来较大开销:
- 主节点需要生成 RDB 文件;
- 传输大量数据;
- 从节点需要清空内存重新加载 RDB。
- 增量复制则更轻量:
- 只要复制偏移量还在主节点的 backlog 范围内,从节点只需接收并执行缺失的指令即可,无需加载全部数据。
Redis 会尽量通过增量复制来节省资源,只有当增量复制无法满足需求时才会降级为全量复制。
4. 总结
- 全量复制
- 适用于从节点初次连接主节点、从节点断线过久导致 backlog 覆盖或主节点重启导致 runid 变化的情形。
- 流程是:从节点请求 →主节点生成 RDB 并发送 → 从节点加载 RDB →同步增量数据。
- 增量复制
- 从节点在与主节点短暂断线且 backlog 尚在有效范围时使用。
- 流程是:从节点携带 offset 请求 →主节点对比 offset 与 backlog → 如果在有效范围则只发送缺失命令流并执行。
在实际生产环境中,通过合理设置 repl-backlog-size 和其他相关配置,可以最大限度地使用增量复制,从而降低全量复制带来的开销和对集群性能的影响。
以下内容基于 Redis 经典(单机版)主从结构(非 Cluster 模式)进行讲解,涵盖了 Redis 主从同步的完整过程,包括初次连接、全量复制、增量复制、日常同步四个阶段。希望能帮助你更系统地理解 Redis 的主从同步机制。
7.7 主从同步完整过程
1. 主从复制的基本原理
Redis 主从结构中,主节点(Master) 负责处理写操作,并将数据变化(命令流)传播给 从节点(Slave)。
- 主节点:只读/读写皆可(视具体配置而定),但通常在生产环境下只对外提供写操作;
- 从节点:只读,避免写与主节点写冲突;从节点的作用通常是分担读压力或在主节点出现故障时快速接管。
Redis 的复制主要通过以下关键要素来维持同步:
- 复制偏移量(offset)
- 主节点会为自己发送的每一条数据(写命令)维护一个全局递增的 offset;
- 从节点也会维护自身已经复制到的 offset;
- 双方通过对比 offset 来确定是否有数据缺失、是否需要补齐。
- 运行 ID(runid)
- 每个 Redis 进程在启动时都会生成一个唯一标识 runid;
- 从节点会记录和识别当前所连主节点的 runid,用以区分不同的主节点。
- 复制积压缓冲区(replication backlog)
- 在主节点上维护的一个环形缓冲区,用于缓存最近一段时间的写操作(命令流);
- 当从节点短暂断线后重连,如果缺失的部分数据仍在该缓冲区内,就可以直接通过此缓冲区补齐,免去全量复制带来的开销。
2. 从节点启动时的主从同步流程
当一个新的从节点启动,或一个断线已久的从节点重新加入时,通常会经历一个 “全量复制” 的过程来获取主节点上的全部数据,再进入持续增量复制阶段。
2.1 从节点与主节点的初始握手
- 从节点配置了
slaveof <master-host> <master-port>(或replicaof <master-host> <master-port>)后,在启动时会尝试向主节点发起连接; - 从节点发送
PING:在正式开始复制前,从节点通常会先与主节点进行一次简单的“心跳”请求(PING),以检测网络和鉴定主节点是否可访问; - 主节点返回
PONG:若主节点可访问,会回复PONG,握手阶段成功。
2.2 触发全量复制(Full Resynchronization)
在握手完成后,从节点会向主节点发送 PSYNC ? -1 命令,意即“我没有任何已知的 offset,也不知道你的 runid,需要进行一次全量复制”。
- 如果主节点检测到从节点的请求无法进行部分(增量)复制(因为是新加入或 backlog 不可用),则会返回
FULLRESYNC <master_runid> <offset>表示需要进行全量复制。 - 从节点收到
FULLRESYNC后,会记录下主节点的 runid 和 offset(从节点此时的本地 offset 也将重置)。
2.3 主节点生成 RDB 并发送
- 主节点执行
BGSAVE- 主节点
fork()出子进程将内存快照保存为 RDB 文件; - 在生成 RDB 过程中,主节点还会将新产生的写命令存储到 复制缓冲区(或称 “复制积压缓冲区 + 额外 buffer”)里,以便后续给从节点补充“快照生成阶段”遗漏的写操作;
- 主节点
- 主节点将 RDB 文件通过网络发送给从节点
- 当子进程完成 RDB 文件的生成后,主节点会把 RDB 文件直接通过 socket 流方式发送给从节点(而不一定是先存盘再读取,这在高版本 Redis 中是可配置/可优化的)。
2.4 从节点加载 RDB
- 清空本地数据
- 为确保和主节点数据完全一致,从节点会先清空内存中的旧数据;
- 加载 RDB 文件
- 从节点将接收到的 RDB 文件内容直接写到内存中,恢复成与主节点一致的数据状态。
2.5 传输并执行增量指令
- 在 RDB 传输和加载的这段时间里,主节点不断有新的写命令被执行,这些命令被存储在主节点的复制缓冲区;
- 从节点加载完 RDB 后,主节点会把复制缓冲区中的所有新写命令发送给从节点;
- 从节点按顺序执行这些写命令,让自身的数据状态追赶到主节点当前最新状态。
2.6 进入持续复制阶段
- 完成上述过程后,主从数据一致;
- 主节点针对后续所有写操作(命令流)会实时发送给从节点,从节点也会实时执行这些操作,使得主从数据保持同步。
小结:当从节点第一次连到主节点或断线时间过久时,就会触发这样一次较为消耗资源的 全量复制。
3. 日常短暂断线时的增量同步流程
在大多数情况下,Redis 会尽量通过 增量复制(Partial Resynchronization) 来同步,以避免全量复制带来的大规模数据传输和主节点磁盘/CPU开销。增量复制发生在:
- 从节点与主节点的网络出现短暂断线;
- 主节点重启后 runid 不变(2.8+ 的 “主节点部分重同步” 场景,但如果重启后 runid 改变则无法增量);
- 主节点保存了足够的 backlog 数据。
3.1 触发增量复制
当从节点重新连上主节点后,会发送命令:
PSYNC <master_runid> <offset>- 其中
<master_runid>为从节点上一次记录的主节点 runid; <offset>为从节点已复制到的最后一个字节/命令偏移量。
3.2 主节点判断能否增量
主节点收到上述请求后,会根据以下条件判断:
- runid 是否匹配
- 如果从节点携带的 runid 和主节点本身的 runid 相同,说明还是同一个主节点(或主节点重启但 runid 复用了);如果不匹配,就必须走全量复制。
- offset 是否在 backlog 范围内
- 主节点检查自身的 replication backlog,判断该 offset 是否仍在 backlog 的可用范围内:
- 如果 backlog 中依然保存了 offset 之后所有的命令,则可以执行“增量复制”;
- 如果已经被覆盖(说明从节点缺失太多数据),只能退回到全量复制。
- 主节点检查自身的 replication backlog,判断该 offset 是否仍在 backlog 的可用范围内:
3.3 执行增量复制
- 如果判断可以增量:主节点就从 backlog 中取出 offset 之后的命令,发送给从节点;
- 从节点依次执行,更新自身数据并将 offset 往前推进;
- 当 backlog 的缺失命令全部执行完毕后,从节点与主节点再次到达一致状态,进入正常的实时复制阶段。
增量复制只需发送丢失的数据指令,不需重新加载全量数据,大大减少了网络和 CPU 等资源的开销。
4. 正常主从复制(持续同步)
在从节点完成全量或增量数据同步后,就进入了持续复制阶段。此时,主节点对外执行的写操作会同时复制给所有从节点,从节点实时(或在毫秒级延迟内)执行这些写命令,保证主从数据最终一致。
这一阶段包含以下细节:
-
命令传播
- 主节点每收到一条写命令,在处理完后会将该命令写入自己的复制流,并将其发送给所有处于“在线”状态的从节点;
-
从节点应用命令
- 从节点收到命令后,顺序执行相应的写操作,保证数据状态与主节点同步;
-
心跳机制
- 主从之间会周期性发送
REPLCONF ACK <offset>等命令来维持心跳,并更新双方的 offset;
- 主从之间会周期性发送
-
故障转移/选举
(如有 Sentinel 或 Redis Cluster)
- 若主节点故障或网络不可达,从节点可在某些机制(比如 Sentinel)下被提升为新的主节点,其他从节点改为复制这个新的主节点,实现自动故障转移。
5. 小结
- 初次连接或大范围数据丢失时,从节点会进行 全量复制:
- 主节点
BGSAVE生成 RDB 并发送给从节点; - 从节点加载 RDB;
- 同步全量复制期间主节点的增量命令;
- 进入持续复制阶段。
- 主节点
- 短暂断线且 backlog 数据仍有效时,可以 增量复制:
- 从节点携带上次已知的 runid 和 offset 发起
PSYNC请求; - 若 runid 相同且 offset 在 backlog 范围内,则只需发送缺失的命令;
- 完成缺失命令后进入持续复制阶段。
- 从节点携带上次已知的 runid 和 offset 发起
- 持续复制阶段下,主节点的所有写操作会同时广播给从节点,从节点实时执行,以保持与主节点数据一致。
在实际生产环境中,我们会通过合理设置 repl-backlog-size 等参数来增大 backlog 缓冲,尽可能提高增量复制的成功率,降低全量复制带来的压力和风险。这样能够使主从架构在高并发、网络抖动等环境下更稳定地运行。
8.Redis 级联复制
在 Redis 中,所谓“级联复制”(有时也被称作“链式复制”或“多级复制”),是指一个从节点(Replica)不仅可以从主节点(Master)复制数据,也可以从另一个从节点上再复制数据,从而形成一条主—从—从的“链式”结构。这样做的目的通常是为了 分担主节点的网络负载 或 应对跨地域/网络层级的部署需求。
一、级联复制的基本概念
-
传统主从结构
- 典型的 Redis 主从复制拓扑是 “一主多从(Star 型)”,所有从节点都直接从主节点复制数据。
- 优点:拓扑简单,便于运维,主节点故障后也能较快地进行故障转移。
- 缺点:当从节点数量很多时,主节点的网络带宽和 CPU 负载压力会增大。
-
级联复制结构
-
在级联复制模式下,可以将一部分从节点配置为 “从节点的从节点”,即:
Master -> Replica1 -> Replica2 -> Replica3 -> ... -
对于 Replica2 而言,它的“上游”节点就是 Replica1,Replica2 会把 Replica1 当作“Master”来复制数据;而 Replica1 实际又是 Master 的从节点。以此类推,可以形成多级 “链式” 复制。
-
-
适用场景
- 跨地域/跨机房:有时希望把数据先从主机房(Master)复制到同城/同可用区的某个从节点,再从这个从节点复制到更远的分支机房,从而减小跨地域的网络延迟和带宽压力。
- 减少 Master 压力:当主节点带宽或 CPU 资源较有限,而需要部署大量只读副本,可考虑让某些副本从“二级副本”甚至“三级副本”拉取数据。
二、Redis 级联复制的工作原理
Redis 的主从复制是通过 PSYNC(部分重同步)机制来实现的,核心包括:
- 复制偏移量(Replication Offset)和主从 ID(Replication ID)
- 每个节点都有一个不断递增的复制偏移量
offset,Master 在发送写操作时更新 offset,并在 backlog 中保存一段时间的操作命令历史。 - 当 Replica(从节点)向上游请求同步时,会带上自己当前的 offset 和上次复制的 Master Replid,通过这二者来判断是否能进行部分重同步(PSYNC)还是需要全量复制。
- 每个节点都有一个不断递增的复制偏移量
- 全量复制 vs. 部分重同步
- 当一个从节点首次连接到上游节点(不管该上游是 Master 还是另一个 Replica),若无法满足部分同步条件,就会触发全量复制(即发送 RDB + 后续增量命令)。
- 后续短暂断线重连时,如果上游节点的 backlog 还保留着从节点缺失的命令,就能走部分重同步,减少网络和 IO 开销。
- 多级复制的本质
- 不管“上游”节点是 Master 还是另一个 Replica,对下游节点而言都是一个“发送复制数据”的源节点。Redis 内部并没有把“从节点的从节点”当成一种特别的角色,每个 Replica 只知道自己要从“上游”拉取数据并保持同步即可。
三、Redis 级联复制的配置步骤
假设我们有如下节点:
- Master:IP 为
192.168.1.10,端口6379 - 一级从节点(Replica1):IP 为
192.168.1.11,端口6379 - 二级从节点(Replica2):IP 为
192.168.1.12,端口6379
1. 配置 Master
在 Master 的 redis.conf 中,通常无需额外开启什么。只要确保能正常对外提供服务即可。若 Master 设有密码,则需要在从节点配置对应的 masterauth。
2. 配置一级从节点(Replica1)
-
在其
redis.conf或启动参数中指定:replicaof 192.168.1.10 6379 # 如果 Master 设置了密码: masterauth -
启动后,Replica1 会从 Master 拉取全量数据。可通过
INFO replication查看master_link_status: up即表示同步成功。
3. 配置二级从节点(Replica2)
-
在其
redis.conf中,让它去复制 “一级从节点(Replica1)”:replicaof 192.168.1.11 6379 # 如果 Replica1 也启用了 requirepass(对外访问),则需要: masterauth -
注意,这里不是配置
replicaof 192.168.1.10 6379,而是指向 “一级从节点”。 -
启动后,Replica2 会把 Replica1 当作“Master”,向它进行全量或部分重同步。
4. 验证级联复制
-
在真正的 Master 上插入一个测试 Key:
redis-cli -h 192.168.1.10 -p 6379 SET test_key "hello_cascading" -
先在一级从节点(Replica1)验证:
redis-cli -h 192.168.1.11 -p 6379 GET test_key # 返回 hello_cascading -
再在二级从节点(Replica2)验证:
redis-cli -h 192.168.1.12 -p 6379 GET test_key # 返回 hello_cascading -
如果都能查到相同数据,说明级联复制已生效。
四、级联复制的优缺点
1. 优点
- 分担主节点压力
- 如果从节点很多,都直接连到 Master,Master 的网络带宽和 CPU 可能吃紧。级联后,只有一级 Replica 跟 Master 同步,其他节点从该 Replica 同步,可以显著减轻 Master 的负载。
- 跨网络 / 跨机房优化
- 在多机房部署场景下,可以先在本地机房搭建一个从节点,再让其他远程机房的节点从这个本地从节点拉取数据,减少跨数据中心的网络消耗。
2. 缺点
- 增加复制延迟
- 数据从 Master 同步到 Replica1,再到 Replica2,会比直接从 Master 同步多一层延迟,且链越长,延迟越大。
- 潜在单点风险
- 如果中间级节点(例如 Replica1)出现故障,那么它下游的所有 Replica2、Replica3 等都会无法获取更新,需要及时重新配置或修复。
- 运维复杂度更高
- 需要维护一条链上的健康状况,了解每一级节点的状态;故障转移(故障切换)场景下也更复杂。
五、级联复制的故障与运维要点
- 监控每一级节点的复制状态
- 使用
INFO replication命令查看master_link_status是否为up; - 监控
role、repl_backlog_size、master_sync_in_progress以及复制偏移量。
- 使用
- 避免链条过长
- 虽然理论上可以多级复制,但一般不建议层数超过 2~3 级。过长的链会带来较大的复制延迟和较高的故障风险。
- 自动故障转移(Sentinel / Cluster)
- 若要实现自动或半自动的故障转移,可以结合 Redis Sentinel 或者 Redis Cluster。
- 需要注意:Redis Sentinel 在做主从切换时,默认只关注“真正的 Master”与“其直连从节点”的关系;如果使用级联复制,还需要确保 Sentinel 能正确感知到各级节点的状态,以便在故障时进行合适的切换逻辑。
- 网络与带宽规划
- 在跨机房或跨网络环境下,需要关注各个节点间的带宽和延迟,确保不会因为网络问题导致频繁的复制中断或超时。
- 资源使用与扩容
- 级联复制可以减少 Master 带宽或 CPU 压力,但并没有降低整体的资源消耗,尤其在接收数据的一方(Replica1)可能会有额外的网络 I/O 负担。
六、总结
Redis 支持“多级”或“级联”复制,即让某个从节点继续作为其他从节点的上游,从而形成一条或多条复制链。其核心机制与普通主从一致,都依赖 PSYNC 进行全量或部分重同步;区别只在于从节点的 “master” 变成了另一个 Replica。
- 如何配置:在二级或更多级的从节点上,通过
replicaof <上游节点IP> <端口>指向另一个 Replica 即可。 - 何时使用:最常见于大规模只读节点部署、跨机房同步、或需要减少 Master 压力的场景;但要权衡延迟和运维复杂度。
- 故障与运维:需要对每一级节点都进行监控,一旦上游节点挂了,下游节点也会同步中断,需要手动或使用 Sentinel/Cluster 自动重建复制关系。
总的来说,级联复制是 Redis 提供的一个灵活选项,但在多数常见部署中(尤其是云环境带宽和资源充足的情况下),仍以“星型”的主从架构为主。如果确实有跨网络或带宽受限场景,需要谨慎设计和规划级联的层级、监控及故障转移策略。
9.Redis 哨兵(Sentinel)

Redis Sentinel(哨兵)是 Redis 官方提供的一套高可用(High Availability)解决方案,用于监控多个 Redis 服务器实例并在主节点出现故障时进行自动故障转移(Failover)。Sentinel 的目标是保证集群的健壮性和可用性,帮助运维人员减少手动干预。
一、核心功能
- 监控(Monitoring)
Redis Sentinel 会持续监控主节点和从节点的状态是否正常。一旦检测到主节点无法正常响应,Sentinel 会标记该节点为主观下线(Subjectively Down),并在多个 Sentinel 达成一致后,进一步认定其为客观下线(Objectively Down)。 - 通知(Notification)
当 Sentinel 识别到主节点宕机或故障转移发生时,它可以通过发布订阅频道(Pub/Sub)、邮件、Webhook 等方式通知运维或相关组件,以方便及时处理。 - 自动故障转移(Automatic Failover)
当主节点被判定不可用时,Sentinel 会从从节点中挑选一个合适的节点将其升级为新的主节点,并重新配置其他从节点指向新的主节点,保证应用能够继续使用 Redis 服务。 - 配置提供(Configuration Provider)
客户端可以通过 Sentinel 获取当前可用的主节点信息,客户端不需要提前知道具体的主节点地址,而是直接向 Sentinel 请求,从而获得更动态的部署方式。
二、工作原理
Sentinel 检测到主节点出现故障后,会经历以下几个重要步骤:
- 主观下线(Subjectively Down, SDOWN)
- 每个 Sentinel 会定期向主从节点发送
PING命令。 - 如果在配置的时间(
down-after-milliseconds)内没有收到有效回复,则该 Sentinel 标记此节点为“主观下线”。
- 每个 Sentinel 会定期向主从节点发送
- 客观下线(Objectively Down, ODOWN)
- 当一个 Sentinel 将主节点标记为 SDOWN 后,会询问其他 Sentinel 是否也认为主节点不可用。
- 如果有足够多(达到
quorum配置)的 Sentinel 都认为主节点已下线,则将主节点标记为“客观下线”,确定主节点确实无法对外服务。
- 故障转移选举
- 在检测到主节点 ODOWN 后,Sentinel 之间会先进行一次领导者(Leader)选举:谁来执行故障转移。
- 通过 Raft-like 的投票机制(基于多轮投票、配置时间限制等),选出一个 Sentinel 成为故障转移的执行者。
- 晋升新主节点
- 领导者 Sentinel 会从现有的从节点(Slave)中挑选最合适的一个(考虑
slave-priority、复制偏移量、延迟、最近是否断线等因素)晋升为新的主节点。 - 晋升完成后,Sentinel 会向其他从节点发送命令,将它们的复制目标指向新的主节点。
- 领导者 Sentinel 会从现有的从节点(Slave)中挑选最合适的一个(考虑
- 通知与更新
- 故障转移成功后,Sentinel 会更新自身的配置,并广播新的主节点信息。
- 其他非领导者 Sentinel 收到更新信息后,也会更新本地配置;客户端如果通过 Sentinel 获取主节点信息,也会知道新的主节点地址,从而实现自动切换。
- 老主节点重新上线
- 当故障恢复后,原主节点会以从节点(Slave)身份自动加入集群,继续对新主节点进行复制。
- 这样,集群又恢复到完整的主从结构,并保持高可用。
三、典型架构
通常在生产环境中,至少部署 3 个 Sentinel 节点(奇数个),奇数个是为了防止出现脑裂现象,分别监控同一个主从集群。这样可以提高一致性和容错能力。
- 主从节点(Master-Slave)
- 至少一个主节点,若干从节点,用于数据复制和负载均衡。
- Sentinel 集群
- 建议 3 个或 5 个 Sentinel,保证在出现网络分区或单点故障时仍能做出正确决策并完成自动故障转移。
- 客户端应用
- 客户端可以配置通过 Sentinel 获取主节点地址,而无需提前硬编码主节点信息。
四、配置要点
详细配置过程参考《Redis的一主二从三哨兵》。
在 sentinel.conf 或相应的配置文件中,需要定义监控的主节点信息,以及故障转移的一些关键参数。
-
监控主节点
sentinel monitor mymastermymaster:自定义的监控主节点名称。<master-ip>:主节点 IP。<master-port>:主节点端口。<quorum>:判断主节点客观下线所需的最少 Sentinel 数。
-
下线判定时间
sentinel down-after-milliseconds mymaster 5000- 指定多少毫秒内未收到正常响应后,标记该主节点为“主观下线”。
-
故障转移超时
sentinel failover-timeout mymaster 60000- 指定在执行故障转移时,若在此时间内无法完成,Sentinel 会放弃当前故障转移流程。
-
通知脚本
sentinel notification-script mymaster /path/to/notify.sh- 在发生主节点故障或故障转移时,Sentinel 会调用该脚本。
-
故障转移脚本
sentinel reconfig-script mymaster /path/to/reconfig.sh- 在执行故障转移后,可运行该脚本完成额外的重新配置操作(如更新负载均衡器等)。
-
手动下线redis节点
[root@Rocky9.4 ~]#redis-cli -p 26379
127.0.0.1:26379> SENTINEL FAILOVER mymaster
OK
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=10.0.0.40:6379,slaves=2,sentinels=3
# 修改slave优先级
27.0.0.1:6379> CONFIG SET replica-priority 70
OK
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:10.0.0.41
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:3991359
slave_repl_offset:3991359
slave_priority:70
......详细的配置参数
# 三台机器全部这样配置
# 源码编译不会在/apps/redis/etc/下生成sentinel.conf这个文件,需要从源码里面拷贝一份
[root@redis_master redis]#cp /root/redis-7.4.1/sentinel.conf /apps/redis/etc/sentinel.conf
[root@redis_master redis]#vim /apps/redis/etc/sentinel.conf
port 26379
bind 0.0.0.0
daemonize yes
pidfile "/apps/redis/run/redis-sentinel.pid"
logfile "/apps/redis/log/sentinel_26379.log"
dir "/tmp" # 工作目录
sentinel monitor mymaster 10.0.0.42 6379 2 # mymaster是当前一组主从复制集群的名字,sentinel可以监控多组 2代表有两个sentinel认为宕机就可以选举了
sentinel auth-pass mymaster 123456 # mymaster集群中master的密码,这行一定在上面那行的下面
sentinel down-after-milliseconds mymaster 3000 #判断mymaster集群中所有节点的主观下线的时间,单位:毫秒,建议3000
sentinel parallel-syncs mymaster 1 #发生故障转移后,同时向新的master同步数据的slave数量,数字越小总同步时间越长,但可以减轻新master的负载压力
sentinel failover-timeout mymaster 180000 #所有slave指向新的master所需的超时时间,单位:毫秒 三分钟
sentinel deny-scripts-reconfig yes # 禁止修改脚本五、Sentinel 内部定时任务
在 Redis Sentinel 的内部实现中,有多个定时(周期性)任务来驱动上述流程。可以简要地将其理解为以下几个重要的“循环”或“Timer”:
- 定时 PING 检测
- Sentinel 会按照一定频率(默认 1 秒一次,或由配置决定)向主节点、从节点以及其他 Sentinel 发送
PING命令。 - 若节点在
down-after-milliseconds内没有响应,则标记为主观下线(SDOWN)。这是主观下线侦测的核心机制。
- Sentinel 会按照一定频率(默认 1 秒一次,或由配置决定)向主节点、从节点以及其他 Sentinel 发送
- 定时 INFO 收集
- Sentinel 也会周期性地向 Redis 节点发送
INFO命令,以获取节点版本、复制偏移量、角色(主 / 从)、所监控的其他节点信息等。 - 这些信息有助于判断哪个从节点最适合被晋升为新主节点(例如优先级、复制偏移量等)。
- Sentinel 也会周期性地向 Redis 节点发送
- Sentinel 之间的 HELLO 信息交换
- 不同 Sentinel 之间会通过发布订阅(
__sentinel__:hello频道)来交换信息。 - Sentinel 周期性地把自己监控的主从节点信息发布到频道,同时也从频道中接收其他 Sentinel 的信息,从而实现对集群拓扑的一致认知。
- 不同 Sentinel 之间会通过发布订阅(
- 选举与故障转移状态机定时检查
- 当 Sentinel 认为主节点客观下线,会启动故障转移流程。
- 这一流程也是通过定时任务逐步推进(如:发起投票->收集票数->如果超时则重试->成功后晋升从节点),直到完成或超时失败。
- 配置文件定时保存
- Sentinel 会在故障转移完成后或配置更新后,异步地把最新状态写入到本地配置文件(如
sentinel.conf),以防止进程重启后丢失最新的拓扑配置。
- Sentinel 会在故障转移完成后或配置更新后,异步地把最新状态写入到本地配置文件(如
这些定时任务共同构成了 Sentinel 的“感知-决策-执行”的循环:感知节点状态、决策是否需要故障转移、执行切换并通知集群。
六、使用与维护建议
- 部署建议
- 为保证高可用,每个 Sentinel 都应该与 Redis 节点分布在不同的物理机或容器中,避免单点故障或网络分区对可用性的影响。
- 建议使用奇数个 Sentinel(至少 3 个),防止脑裂(split-brain)问题。
- 客户端正确使用
- 推荐客户端直接连接 Sentinel 获取主节点信息(通过
SENTINEL get-master-addr-by-name <master-name>)。 - 部署应用时保证在主节点切换后,客户端可以尽快感知到新的主节点,尽量减少服务中断。
- 推荐客户端直接连接 Sentinel 获取主节点信息(通过
- 监控及报警
- 时刻关注 Sentinels 自身的健康状况:Sentinel 之间的网络连通性、各个 Redis 节点的延迟情况等。
- 合理设置报警机制(如日志监控、Prometheus + Grafana 监控等),在出现告警时及时排查网络和系统问题。
- 版本兼容与升级
- 不同版本的 Redis 可能在 Sentinel 功能上存在差异,部署前要查看官方文档确认兼容性。
- 升级 Redis 或 Sentinel 时,要先在测试环境演练并做好回滚预案。
七、总结
Redis Sentinel 通过持续监控、自动通知与故障转移、配置中心等功能,帮助 Redis 在主从模式下实现高可用。它能最小化人工干预,确保当主节点出现故障后,系统能自动完成从节点晋升、集群重新配置等关键步骤,从而最大程度地保证业务的连续性。在生产环境中,合理地进行 Sentinel 部署、配合主从架构及应用配置的优化,将显著提升整个 Redis 集群的可靠性和稳定性。
八、客户端连接 Sentinel 工作原理
在使用 Redis Sentinel 进行高可用部署时,客户端并不是直接去“猜”主节点(master)的地址,也不会直接同时连所有从节点(replica)来判断谁是主节点,而是通过向 Sentinel 查询当前可用的主节点地址,再去连接该主节点进行读写操作。其核心思想是“客户端将主节点发现和故障转移逻辑交给 Sentinel 去做”,客户端只需要在初始化时知道一组 Sentinel 的地址,就能在主节点发生变化时自动感知并切换到新的主节点。
1. 整体流程概览
- 客户端初始化:
客户端会被配置好一个或多个 Sentinel 的地址列表(IP:PORT),以及一个代表“主节点名称”(masterName)的标识。 - 客户端向 Sentinel 查询当前主节点:
客户端向 Sentinel 发送命令(例如SENTINEL get-master-addr-by-name <masterName>),获取到当前主节点的 IP 和端口。 - 客户端连接 Redis 主节点:
客户端根据上一步返回的 IP 和端口,建立与当前主节点的连接,用于读写操作。 - Sentinel 监控和故障转移:
- Sentinel 在后台持续监控 Redis 主从节点的健康状况。如果主节点不可用,Sentinel 选举出一个从节点晋升为新的主节点,并更新内部配置信息。
- Sentinel 会对外暴露新的主节点信息,客户端再次通过 Sentinel 查询(或在连接异常时重新查询),就能拿到新主节点的地址。
- 客户端重新连接:
如果客户端在使用过程中发现原主节点断开(网络异常、超时等),会再去询问 Sentinel 最新的主节点地址,从而与新主节点建立连接,实现故障恢复和高可用。
通过以上步骤,Redis 集群在后端完成了主从切换和故障转移,而客户端只需要确保能访问至少一个存活的 Sentinel,就可以拿到最新的主节点地址,从而无需关心后端节点的实际变化。
2. 工作原理与关键机制
- Sentinel 的监控机制:
- 每个 Sentinel 节点都会与主从节点(以及其他 Sentinel)定期进行 PING 通信,用于确认节点是否存活;
- 当 Sentinel 判断主节点下线(主观下线 + 客观下线),便会发起故障转移流程;
- 多个 Sentinel 通过 Raft 或者“分布式选举协议”类似的方式,协商并最终确定一个从节点作为新的主节点。
- 客户端与 Sentinel 的交互方式:
- 当客户端启动时,通常会使用某些高层次的客户端库或连接池(如 JedisSentinelPool、Lettuce Sentinel、redisson-spring-boot-starter 等)。这些库实现了与 Sentinel 通信的逻辑:
- 逐个尝试连接配置列表中的 Sentinel;
- 向 Sentinel 发送“获取主节点地址”的命令;
- 收到 Sentinel 返回的 (IP, PORT) 后,建立与该 IP:PORT 的 Redis 连接。
- 在正常读写过程中,客户端并不持续与 Sentinel 保持数据操作上的交互,只在连接创建或重连时才再次询问 Sentinel。
- 当客户端启动时,通常会使用某些高层次的客户端库或连接池(如 JedisSentinelPool、Lettuce Sentinel、redisson-spring-boot-starter 等)。这些库实现了与 Sentinel 通信的逻辑:
- 故障转移与主节点更新:
- 一旦主节点发生故障,Sentinel 通过投票和选举机制切换新的主节点;
- Sentinel 内部会更新自己管理的“主节点信息”;
- 客户端如果和原主节点断开或检测到异常,会重新询问 Sentinel,拿到新的主节点地址并连接。
- Sentinel 的高可用:
- 生产环境中往往会部署若干个 Sentinel 进程(一般建议至少 3 个),相互之间协同监控,避免单点故障;
- 只要客户端能够连上任意存活的 Sentinel,就能得到最新主节点的信息。
- 读写分离(可选)
- 有些客户端或框架(例如 Redisson、一些自定义的分布式缓存中间件)支持根据场景选择读从节点或写主节点;
- 但 Sentinel 默认只会向客户端返回主节点地址(用于写入),从节点主要用于冗余或只读场景。
- 如果需要读写分离,通常也需要客户端自行或使用特定的代理层来管理从节点连接。
3. 总结
Redis Sentinel + 客户端的连接工作原理可以概括为:
- 客户端只关注 Sentinel,向其索取主节点地址;
- Sentinel 负责监控 Redis 主从拓扑并在故障时进行自动化的主从切换;
- 客户端在连接或发生异常时,通过 Sentinel 的信息获取新的主节点地址并自动重连。
这种模式避免了客户端自己去判断哪个 Redis 节点是主节点,也不需要在客户端配置中硬编码主节点的 IP/端口,从而极大简化了运维和故障转移的流程,提高了系统整体的高可用性。
下面的内容将为你介绍 Redis Cluster 的实现原理,并对 Redis Cluster 与 Sentinel 在架构设计和使用场景上的差异进行说明。
10.Redis Cluster
Redis Cluster 概述
Redis Cluster 是 Redis 官方提供的分布式解决方案,能够在多台 Redis 节点之间实现数据分片(Sharding)和故障自动转移(Failover),从而在高可用性和可伸缩性方面为 Redis 提供支持。与传统的主从复制模式相比,Redis Cluster 在面对业务快速增长、数据量暴增、服务高可用需求等场景时更具优势。
一、Redis Cluster 实现原理
Redis Cluster 是 Redis 提供的分布式解决方案,旨在解决单机 Redis 在数据量、并发量和高可用方面的瓶颈。它可以在多台服务器之间进行数据分片(sharding),并提供一定程度的故障转移能力。
1. 核心特性
- 数据分片(Sharding):
Redis Cluster 将整个 key 空间划分为 16384 个哈希槽(hash slot,范围为 0~16383)。每个节点可分配到若干槽,并负责存储该槽内的所有数据。客户端访问某个 key 时,通过对 key 进行 CRC16 运算并对 16384 取模来定位该 key 所在的槽位,然后直接请求对应节点。 - 高可用(Replica):
- Redis Cluster 通过为每个主节点(master)配置一个或多个从节点(replica)来进行冗余备份提高可用性。
- 当某个主节点失效时,其从节点会被自动提升为主节点(Failover)。
- 无中心节点:
Redis Cluster 没有专门的中心控制节点,集群中的每个节点既存储数据又保存集群信息,节点之间通过 Gossip 协议(消息交换协议)定期与其他节点通信以保持拓扑更新。集群中不存在单点故障的“中心”节点,一定程度上提升了系统的健壮性。 - Gossip 协议 & 心跳检测:
- 每个节点周期性向其他节点发送 PING 消息并等待回复(PONG),通过超时判定一个节点是否下线。
- 大多数主节点(master)同意某节点下线,才能标记该节点为 FAIL 状态并进行故障转移。
- 客户端重定向
- 若客户端访问了错误的槽位,集群节点会返回
MOVED或ASK重定向信息,告诉客户端正确的节点地址。 - 这样客户端可以自动重试,将请求发往正确的节点。
- 若客户端访问了错误的槽位,集群节点会返回
- 读写拆分
在 Redis Cluster 中,客户端的写请求会自动发送到目标主节点,而读请求则可以通过客户端自行配置来从从节点进行读取,从而减轻主节点压力,提高整体的读吞吐量。 - 线性扩展
Redis Cluster 通过简单地增加或减少节点,并对集群中的哈希槽重新分配(Rebalance)来实现扩展。与单节点或者简单主从复制方式相比,Redis Cluster 可以更有效地利用多机资源,从而提高吞吐量和存储容量。
2. Redis Cluster 的架构
一般来说,一个 Redis Cluster 至少需要 3 个主节点 来完成基本的故障自动转移。此外,为了保证高可用,每个主节点可配置一个或多个从节点。如下是一个示例拓扑结构:
+---------+ +---------+ +---------+
| Master1 | | Master2 | | Master3 |
| Slot | | Slot | | Slot |
| 0-5460 | | 5461-10922 | | 10923-16383 |
+----+----+ +----+----+ +----+----+
| | |
+v+ +v+ +v+
|R| |R| |R|
Slave1 Slave2 Slave3
-
主节点(Master):存储并管理哈希槽的数据,响应客户端的读写请求。
-
从节点(Slave):复制主节点的数据。当主节点发生故障时,从节点会自动升级为主节点。
-
Gossip 协议:集群节点之间通过 Gossip 协议交换彼此的心跳和槽位分配等信息,确保集群拓扑的一致性。
二、Redis Cluster 的数据分片机制
Redis Cluster 使用预先定义好的 16384 个哈希槽 来进行数据分片。
- 当客户端执行
SET key value等命令时,Redis 会先对key进行 CRC16 运算,然后再将结果对 16384 取模,得到对应的哈希槽号(槽 ID)。 - Redis 决定哪个节点负责管理这些哈希槽,进而决定数据存放在哪个节点上。
- 当需要进行集群扩容或缩容时,可通过
redis-cli命令对哈希槽进行重新分配(Rebalance),尽量平衡各个节点的负载。
示意:
CRC16(key) % 16384 --> slot_id
slot_id 由哪个节点负责四、Redis Cluster 的高可用机制
- 主从复制(Master-Replica Replication)
当某个主节点不可用时,对应的从节点会在完成一定条件和集群投票后自动升级为主节点,实现故障转移。 - 故障检测(Failure Detection)
- PFAIL(主观下线):若节点 A 在
cluster_node_timeout时间内没有收到节点 B 的正确回复,节点 A 会将 B 标记为主观下线(PFAIL)。 - FAIL(客观下线):若多数节点(包括 A)都认为 B 下线,则会将 B 标记为客观下线(FAIL)。此时便会触发故障转移流程。
- PFAIL(主观下线):若节点 A 在
- 故障转移(Failover)
当一个主节点被客观下线后,集群会发起选举,等待符合条件的从节点成为新的主节点。新的主节点接管原主节点的哈希槽,并恢复对外提供读写服务。
二、Redis Sentinel 原理
Redis Sentinel 是针对 Redis 的高可用监控与自动故障转移工具,更常用于单主多从架构。它本身并不提供数据分片能力,而是侧重监控和故障转移。
- 监控主从架构:
Sentinel 不断地 PING 主节点、从节点以及其他 Sentinel,以检测节点是否存活。 - 主观下线和客观下线:
- 当一个 Sentinel 认为主节点无法访问,就会标记其为“主观下线”。
- 如果其他 Sentinel 也同意该主观下线,则将其升级为“客观下线”,启动故障转移流程。
- 故障转移流程:
- Sentinel 会通过选举机制在剩余的从节点中选出一个最合适的“晋升为主节点”的节点。
- 更新配置,并通知所有从节点改为复制新的主节点。
- 这期间,会向客户端广播新的主节点信息。
- 通知客户端
- 客户端(或者客户端的连接池)只需要连接 Sentinel,而无需手动指定主节点。
- 当主节点切换时,客户端可以通过 Sentinel 查询最新主节点地址,实现自动重连。
- Sentinel 的高可用本身
- 通常生产环境会部署多个 Sentinel 进程,互为备份且通过投票方式确认主节点是否故障。
- 只要有一个 Sentinel 存活,就可向客户端提供最新的主节点信息。
三、Redis Cluster vs Sentinel 的区别
- 核心定位/目标
- Redis Cluster:
- 主要解决 数据分片(水平扩容) 的问题,同时提供基础的高可用。
- 适用于数据量大、吞吐量高,需要进行分布式存储和集群扩展的场景。
- Sentinel:
- 主要用于 单个 Redis 主从架构的高可用;不提供数据分片功能。
- 适用于 Redis 数据规模较小或单节点足以支撑业务,且希望在主节点故障时自动完成主从切换。
- Redis Cluster:
- 数据分布方式
- Redis Cluster:按槽 (hash slot) 进行数据分片,支撑大数据量和高并发场景。
- Sentinel:无分片,通常只是一主多从(或多对主从),数据在所有从节点之间完全复制。
- 故障转移机制
- Redis Cluster:节点间通过 Gossip 协议互相通信,自动判断失效节点并进行主从切换;集群会将一部分槽转移到新的主节点上。
- Sentinel:Sentinel 进程会监控主从结构,通过投票对主节点下线作出判断,再自动提拔新的从节点为主节点。
- 客户端访问模式
- Redis Cluster:客户端需要支持 cluster 模式,访问时根据 key 自动定位到对应的节点,如果访问错误节点需要重定向。
- Sentinel:客户端只需要连接 Sentinel 并获取当下可用的主节点地址,无需关心后端的节点信息。
- 部署复杂度
- Redis Cluster:需要至少 3 个主节点(加上各自从节点)才能在节点故障时正常工作,还需客户端/应用支持;整体部署配置较为复杂,但可提供水平扩展。
- Sentinel:在单主多从的基础上额外部署若干个 Sentinel 进程即可,相对简单;适合中小规模或单机足以承载的业务场景。
- 适用场景
- Redis Cluster:
- 超大规模数据存储,需要分片扩容;
- 希望在一套 Redis 上承载高并发、高可用且数据量较大的业务。
- Sentinel:
- 数据规模较小或单机可承载,重点是主从的高可用(自动切换);
- 对运维和部署的复杂度要求较低。
- Redis Cluster:
四、总结
- Redis Cluster
- 分布式架构:提供自动分片与基本的高可用;
- 适合数据量大、需要负载均衡、水平扩容的场景;
- 部署更复杂,对客户端要求更高。
- Redis Sentinel
- 监控+高可用:在单主多从的基础上实现自动主从切换;
- 不提供数据分片,只解决高可用;
- 部署简单、对客户端改动较小,适合中小规模业务。
根据项目需求,如果您只是希望 Redis 能够在主节点故障时自动切换到从节点,那么 Sentinel 就足够满足高可用需求;但如果您需要在多台机器间分片存储海量数据并同时兼顾高可用,则需要使用 Redis Cluster。有时也会出现 Redis Cluster + Sentinel 混合使用的场景(但更常见的是 Redis Cluster 自己负责高可用,Sentinel 仅用于传统单体 Redis 部署)。
选择合适的方案,才能在保证高可用的同时兼顾部署成本与运维复杂度。
11.原生命令部署 Cluster
11.1 在所有节点上安装redis并启动cluster功能
# 先通过脚本编译安装Redis,6台Redis
node1 10.0.0.40
node2 10.0.0.41
node3 10.0.0.42
node4 10.0.0.50
node5 10.0.0.112
node6 10.0.0.113
# 手动修改配置文件
bind 0.0.0.0
masterauth 123456 #建议配置,否则后期的master和slave主从复制无法成功,还需在配置
requirepass 123456
cluster-enabled yes #取消此行注释,必须开启集群,开启后Redis 进程会有Cluster标识
cluster-config-file nodes-6379.conf #取消此行注释,此为集群状态文件,记录主从关系即slot范围信息,由redis cluster 集群自动创建和维护
cluster-require-full-coverage no #默认值为yes,设为no可以防止一个节点不可用导致整个cluster不可用
# 修改配置文件相关设置-6台都执行
sed -i.bak -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e '/masterauth/a masterauth 123456' -e '/# requirepass/a requirepass 123456' -e '/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-require-full-coverage yes/c cluster-require-full-coverage no' /apps/redis/etc/redis.conf
# 查看当前redis进程
[root@node5 ~]# ps aux | grep redis
redis 43944 0.3 0.4 134120 7952 ? Ssl 22:09 0:08 /apps/redis/bin/redis-server 0.0.0.0:6379
root 44019 0.0 0.1 6408 2156 pts/0 S+ 22:49 0:00 grep --color=auto redis
# 重启服务-6台执行
[root@node1 ~]#systemctl restart redis
# 再次查看redis进程,发现有cluster标识
[root@node1 ~]#ps aux | grep redis
redis 22009 0.1 0.8 136680 8192 ? Ssl 22:54 0:00 /apps/redis/bin/redis-server 0.0.0.0:6379 [cluster]
root 22033 0.0 0.2 6408 2176 pts/0 S+ 22:54 0:00 grep --color=auto redis
[root@node1 ~]#11.2 执行meet操作实现相互通信
redis-cli -h <已存在节点IP> -p <已存在节点端口> \
cluster meet <新节点IP> <新节点端口>
# 如果在已存在节点ip这台机器上执行, <已存在节点IP> -p <已存在节点端口> 这个可以省略不写在 Redis 集群中,使用
CLUSTER MEET命令是为了将新节点引入到集群中,而一旦新节点被引入,它会与集群中的所有其他节点进行通信。这种通信行为是 Redis 集群设计的结果,因为 Redis 集群本质上是 全连接 的。原因:Redis 集群的全连接机制
- Redis 集群中的节点相互感知:
- 当你通过
CLUSTER MEET命令将一个新节点(比如10.0.0.41)引入到集群中时,这个节点会从你执行CLUSTER MEET的节点那里获取集群的拓扑信息。- 获取到的拓扑信息中包含了集群中所有其他节点的地址。
- 自动建立连接:
- 新加入的节点会主动与集群中其他所有节点建立通信连接(包括心跳包、槽信息同步等)。
- 同样,其他所有节点也会与新加入的节点建立通信连接,从而形成一个全连接的网络。
- 为什么其他节点之间也通信:
- 当你通过
CLUSTER MEET命令将多个节点加入到集群中(比如10.0.0.42和10.0.0.50),这些节点会逐步通过集群的拓扑信息互相发现对方,并建立通信连接。- 因此,不仅本机节点与其他节点通信,所有节点之间都会建立通信。
集群通信设计的目的
Redis 集群设计为全连接网络,其目的是:
- 保证高可用性: 每个节点都能快速检测到其他节点的状态(通过心跳包机制),如果某个节点出现故障,集群可以迅速感知并触发故障转移(failover)。
- 槽分布同步: 每个节点都会知道集群中所有槽(slots)的分布,方便在请求转发或槽迁移时快速找到目标节点。
- 数据一致性: 副本节点需要定期与主节点同步数据,而这种全连接的设计让任何节点都能快速找到需要通信的目标节点。
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
167cc05be9ab506a5fa687e8c9dded4dc2b633a5 :6379@16379 myself,master - 0 0 0 connected
# 执行meet
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster meet 10.0.0.41 6379
root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster meet 10.0.0.42 6379
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster meet 10.0.0.50 6379
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster meet 10.0.0.112 6379
root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster meet 10.0.0.113 6379
# 查看连接情况-与其他5台机器进行通信
[root@node1 ~]#ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 0 10.0.0.40:56390 10.0.0.42:16379
ESTAB 0 0 10.0.0.40:56116 10.0.0.112:16379
ESTAB 0 0 10.0.0.40:22 10.0.0.1:4078
ESTAB 0 0 10.0.0.40:16379 10.0.0.112:55198
ESTAB 0 0 10.0.0.40:16379 10.0.0.113:59318
ESTAB 0 0 10.0.0.40:16379 10.0.0.50:42352
ESTAB 0 0 10.0.0.40:16379 10.0.0.41:46130
ESTAB 0 0 10.0.0.40:35310 10.0.0.41:16379
ESTAB 0 0 10.0.0.40:45462 10.0.0.113:16379
ESTAB 0 0 10.0.0.40:16379 10.0.0.42:38686
ESTAB 0 0 10.0.0.40:52672 10.0.0.50:16379
[root@node1 ~]#ss -nlt
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 511 0.0.0.0:6379 0.0.0.0:*
LISTEN 0 511 0.0.0.0:16379 #集群的工作端口 0.0.0.0:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 511 [::1]:16379 [::]:*
LISTEN 0 511 [::1]:6379 [::]:*
[root@node1 ~]#
# 查看cluster的所有节点相互通信
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster nodes
167cc05be9ab506a5fa687e8c9dded4dc2b633a5 10.0.0.40:6379@16379 myself,master - 0 0 1 connected
5b4b959cec186ee66836d176305b6db55f0ac451 10.0.0.41:6379@16379 master - 0 1736781760000 0 connected
3e9cf23bbfbcbd673d8c5b4abaf3f0e722c94b2a 10.0.0.112:6379@16379 master - 0 1736781758000 5 connected
2758daa041534a8eaef4ac279b430b0836d1e7f4 10.0.0.113:6379@16379 master - 0 1736781761000 4 connected
14468ef2bc32bcf9819b97c72c1c567916a93354 10.0.0.42:6379@16379 master - 0 1736781759894 2 connected
2d56d8d0b9ee2afce646c61577c8b622b87bafe3 10.0.0.50:6379@16379 master - 0 1736781762048 3 connected
[root@node1 ~]#
# 当前状态
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster info
cluster_state:fail
cluster_slots_assigned:0 #无槽位分配
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #已知的节点有6台
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1239
cluster_stats_messages_pong_sent:1279
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:2523
cluster_stats_messages_ping_received:1279
cluster_stats_messages_pong_received:1244
cluster_stats_messages_received:2523
total_cluster_links_buffer_limit_exceeded:0
[root@node1 ~]#11.3 为各个master节点指派槽位范围
方法1:手动分配槽
# 例如给新节点分配 [5461-6000] 这 540 个 slots
redis-cli -a 123456 -h <新节点IP> -p <新节点端口> cluster addslots {5461..6000}方法2:脚本自动化分配
# 创建添加槽位的脚本(为master节点分,slave不需要,会自动同步master)
[root@node1 ~]#cat addslot.sh
#!/bin/bash
host=$1
port=$2
start=$3
end=$4
pass=123456
for slot in $(seq ${start} ${end}); do
echo "Adding slot: $slot"
redis-cli -h ${host} -p ${port} -a ${pass} --no-auth-warning \
cluster addslots ${slot}
done[root@node1 ~]#./addslots.sh 10.0.0.40 6379 0 5460
[root@node1 ~]#./addslots.sh 10.0.0.41 6379 5461 10922
[root@node1 ~]#./addslots.sh 10.0.0.42 6379 10922 16383
#查看集群信息
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster info
cluster_state:ok #当前 Redis 集群的整体状态(ok:集群正常运行。fail:集群有问题(如未分配槽位,或某些节点不可用)。)
cluster_slots_assigned:16384 #分配的槽位数量,Redis 集群总共有 16384 个槽位。( 0,表示没有分配任何槽位,这会导致 cluster_state:fail 的原因之一。)
cluster_slots_ok:16384 #状态正常的槽位数量。
cluster_slots_pfail:0 #部分失败(PFAIL) 的槽位数量。某些节点的状态在短时间内没有响应心跳,但尚未被正式标记为失败。
cluster_slots_fail:0 #失败(FAIL) 的槽位数量。表明某些槽的主节点已经被标记为失败,需要手动修复。
cluster_known_nodes:6 #集群中已知的节点数量,包括主节点和从节点。
cluster_size:3 #当前集群中有几个主节点(通常指已分配槽位的主节点数量)。
cluster_current_epoch:5 #当前集群的全局元数据版本,每当集群拓扑发生变化(如添加或删除节点、重新分配槽位)时,此值会递增。
cluster_my_epoch:1 #当前节点的元数据版本。通常情况下,cluster_my_epoch 反映了该节点的初始化时的分配版本。
cluster_stats_messages_ping_sent:1894 #当前节点已发送的 PING 消息数量,用于与其他节点的心跳通信。
cluster_stats_messages_pong_sent:1953 #当前节点已发送的 PONG 消息数量,用于响应其他节点的 PING 消息。
cluster_stats_messages_meet_sent:5 #当前节点已发送的 MEET 消息数量,用于引入新节点时的握手通信。
cluster_stats_messages_sent:3852 #当前节点发送的所有类型消息的总数量。
cluster_stats_messages_ping_received:1953 #当前节点收到的 PING 消息数量。
cluster_stats_messages_pong_received:1899 #当前节点收到的 PONG 消息数量。
cluster_stats_messages_received:3852 #当前节点收到的所有类型消息的总数量。
total_cluster_links_buffer_limit_exceeded:0 #集群中连接缓冲区超出限制的总次数。如果值大于 0,表示可能有性能瓶颈,需要检查集群的网络连接或缓冲区配置。
#查看集群节点
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster nodes
167cc05be9ab506a5fa687e8c9dded4dc2b633a5 10.0.0.40:6379@16379 myself,master - 0 0 1 connected 0-5460
5b4b959cec186ee66836d176305b6db55f0ac451 10.0.0.41:6379@16379 master - 0 1736782488967 0 connected 5461-10922
3e9cf23bbfbcbd673d8c5b4abaf3f0e722c94b2a 10.0.0.112:6379@16379 master - 0 1736782485000 5 connected
2758daa041534a8eaef4ac279b430b0836d1e7f4 10.0.0.113:6379@16379 master - 0 1736782486000 4 connected
14468ef2bc32bcf9819b97c72c1c567916a93354 10.0.0.42:6379@16379 master - 0 1736782486809 2 connected 10923-16383
2d56d8d0b9ee2afce646c61577c8b622b87bafe3 10.0.0.50:6379@16379 master - 0 1736782487891 3 connected
[root@node1 ~]#若不小心分配错了槽位,如何删除/重新分配?
# 1.删除槽(前提:槽内无数据或不关心数据)
# 删除单个槽
redis-cli -h <wrong_host> -p <wrong_port> -a 123456 cluster delslots 100
# 或删除多个槽
redis-cli -h <wrong_host> -p <wrong_port> -a 123456 cluster delslots 100 101 102
#或者使用批量脚本一次性删除整个区间:
for slot in $(seq 0 5000); do
redis-cli -h <wrong_host> -p <wrong_port> -a 123456 cluster delslots ${slot}
done
#重新分配到正确节点
# 到正确节点 (correct_host, correct_port) 上添加这些槽
for slot in $(seq 0 5000); do
redis-cli -h <correct_host> -p <correct_port> -a 123456 cluster addslots ${slot}
done
如果槽内有数据,该怎么处理?
如果槽内已经存有键值数据,不能直接 delslots,否则会造成集群不一致或报错;此时需要先将数据迁移到目标节点,然后再执行 delslots。简要流程如下:
# 1.将槽标记为待迁移
# 在源节点上执行
redis-cli -h <src_host> -p <src_port> -a <pass> cluster setslot <slot> migrating <dest_node_id>
# 在目标节点执行:
redis-cli -h <dest_host> -p <dest_port> -a <pass> cluster setslot <slot> importing <src_node_id>
# 2.使用 migrate 命令搬移数据(在源节点上,对所有属于该槽位的 key 执行 migrate 到目标节点;也可以用 redis-cli --cluster reshard 交互式自动迁移。或者逐条 DUMP + RESTORE 的方式迁移,也可以脚本化。)
# 3.将槽标记到新节点
# 在目标节点执行:
redis-cli -h <dest_host> -p <dest_port> -a <pass> cluster setslot <slot> node <dest_node_id>
# 在源节点执行 cluster delslots <slot>(如果不再需要该槽)。
# 实际生产环境 中,使用 redis-cli --cluster reshard 或 redis-cli --cluster move 命令会自动完成 importing/migrating 等过程,并避免手动操作失误11.4 指定各个节点的主从关系
# 通过上面cluster nodes 查看master的ID信息,执行下面操作,将对应的slave 指定相应的master节点,实现三对主从节点
# master:10.0.0.40-slave:10.0.0.50(后面的ID对应的master的id,前面写的是slave的ip)
[root@node1 ~]#redis-cli -h 10.0.0.50 -a 123456 --no-auth-warning cluster replicate 167cc05be9ab506a5fa687e8c9dded4dc2b633a5
# master:10.0.0.41-slave:10.0.0.112
[root@node1 ~]#redis-cli -h 10.0.0.112 -a 123456 --no-auth-warning cluster replicate 5b4b959cec186ee66836d176305b6db55f0ac451
# master:10.0.0.42-slave:10.0.0.13
[root@node1 ~]#redis-cli -h 10.0.0.113 -a 123456 --no-auth-warning cluster replicate 14468ef2bc32bcf9819b97c72c1c567916a93354
# 查看节点间关系
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster nodes
167cc05be9ab506a5fa687e8c9dded4dc2b633a5 10.0.0.40:6379@16379 myself,master - 0 0 1 connected 0-5460
5b4b959cec186ee66836d176305b6db55f0ac451 10.0.0.41:6379@16379 master - 0 1736782929293 0 connected 5461-10922
3e9cf23bbfbcbd673d8c5b4abaf3f0e722c94b2a 10.0.0.112:6379@16379 slave 5b4b959cec186ee66836d176305b6db55f0ac451 0 1736782927129 0 connected
2758daa041534a8eaef4ac279b430b0836d1e7f4 10.0.0.113:6379@16379 slave 14468ef2bc32bcf9819b97c72c1c567916a93354 0 1736782930369 2 connected
14468ef2bc32bcf9819b97c72c1c567916a93354 10.0.0.42:6379@16379 master - 0 1736782928211 2 connected 10923-16383
2d56d8d0b9ee2afce646c61577c8b622b87bafe3 10.0.0.50:6379@16379 slave 167cc05be9ab506a5fa687e8c9dded4dc2b633a5 0 1736782927000 1 connected
[root@node1 ~]#redis-cli -a 123456 --no-auth-warning cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3 # 3组集群
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:2376
cluster_stats_messages_pong_sent:2450
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:4831
cluster_stats_messages_ping_received:2450
cluster_stats_messages_pong_received:2381
cluster_stats_messages_received:4831
total_cluster_links_buffer_limit_exceeded:0
[root@node1 ~]#11.5 客户端连接自动计算槽位
# 根据key计算槽位所在哪个master
[root@node1 ~]#redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> set class m44
(error) MOVED 7755 10.0.0.41:6379
# 集群模式连接,会自动重定向写入到计算的机器
[root@node1 ~]#redis-cli -a 123456 -c
10.0.0.41:6379> get class
"m44"
10.0.0.41:6379> set title ceo
-> Redirected to slot [2217] located at 10.0.0.40:6379
OK
10.0.0.40:6379> set cto hello
-> Redirected to slot [7151] located at 10.0.0.41:6379
OK
10.0.0.41:6379> 12.基于redis7.4的redis cluster部署
12.1 在所有节点上安装redis并启动cluster功能
# 先通过脚本编译安装Redis,6台Redis
node1 10.0.0.40
node2 10.0.0.41
node3 10.0.0.42
node4 10.0.0.43
node5 10.0.0.44
node6 10.0.0.45
# 手动修改配置文件
bind 0.0.0.0
masterauth 123456 #建议配置,否则后期的master和slave主从复制无法成功,还需在配置
requirepass 123456
cluster-enabled yes #取消此行注释,必须开启集群,开启后Redis 进程会有Cluster标识
cluster-config-file nodes-6379.conf #取消此行注释,此为集群状态文件,记录主从关系即slot范围信息,由redis cluster 集群自动创建和维护
cluster-require-full-coverage no #默认值为yes,设为no可以防止一个节点不可用导致整个cluster不可用
cluster-node-timeout #节点之间通信超时时间。
# 修改配置文件相关设置-6台都执行
sed -i.bak -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e '/masterauth/a masterauth 123456' -e '/# requirepass/a requirepass 123456' -e '/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-require-full-coverage yes/c cluster-require-full-coverage no' /apps/redis/etc/redis.conf12.2 创建集群
# --cluster-replicas 1 意味着每个主节点会有一个从节点。
[root@node1 ~]#redis-cli -a 123456 --cluster create 10.0.0.40:6379 10.0.0.41:6379 10.0.0.42:6379 10.0.0.43:6379 10.0.0.44:6379 10.0.0.45:6379 --cluster-replicas 1
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 10.0.0.44:6379 to 10.0.0.40:6379
Adding replica 10.0.0.45:6379 to 10.0.0.41:6379
Adding replica 10.0.0.43:6379 to 10.0.0.42:6379
# M=>master S=>slave
M: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots:[0-5460] (5461 slots) master
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[5461-10922] (5462 slots) master
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[10923-16383] (5461 slots) master
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
S: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
replicates 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8
Can I set the above configuration? (type 'yes' to accept): yes #输入yes自动创建集群
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 10.0.0.40:6379)
M: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots:[0-5460] (5461 slots) master #已经分配的槽位
1 additional replica(s) #分了一个slave
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots: (0 slots) slave #slave没有分配槽位
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8 #对应master的ID,也就是10.0.0.41
S: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots: (0 slots) slave
replicates 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@node1 ~]#
# 观察以上结果,可以看到三组master/slave
master:10.0.0.40-->slave:10.0.0.44
master:10.0.0.41-->slave:10.0.0.45
master:10.0.0.42-->slave:10.0.0.43
# 查看主从状态
[root@node1 ~]#redis-cli -a 123456 info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:master
connected_slaves:1
slave0:ip=10.0.0.44,port=6379,state=online,offset=686,lag=0
master_failover_state:no-failover
master_replid:686dd579b02a3975b8c8df7e4f707dfa612519f1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:686
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:686
# 查看指定master节点的slave节点信息
[root@node3 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736845843217 2 connected 5461-10922
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 slave 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 0 1736845844228 1 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 master - 0 1736845842000 1 connected 0-5460
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736845842208 3 connected
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 myself,master - 0 0 3 connected 10923-16383
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736845841000 2 connected
[root@node3 ~]#
# 查看指定master节点的slave节点信息
[root@node1 ~]#redis-cli -a 123456 cluster slaves 767c6fc628516c09dd63fe4dbdc36cecee3808b3
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
1) "12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736845978620 3 connected"
[root@node1 ~]#
# 验证集群的状态
[root@node1 ~]#redis-cli -a 123456 cluster info
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:763
cluster_stats_messages_pong_sent:710
cluster_stats_messages_sent:1473
cluster_stats_messages_ping_received:705
cluster_stats_messages_pong_received:763
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:1473
total_cluster_links_buffer_limit_exceeded:0
[root@node1 ~]#
# 查看任意节点的集群状态
[root@node1 ~]#redis-cli -a 123456 --cluster info 10.0.0.40:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.40:6379 (334ecb12...) -> 0 keys | 5461 slots | 1 slaves.
10.0.0.41:6379 (c9b13ad2...) -> 0 keys | 5462 slots | 1 slaves.
10.0.0.42:6379 (767c6fc6...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
[root@node1 ~]#
12.3 测试写入数据
在运行代码之前,请确保使用以下命令安装
redis-py-cluster:pip install redis-py-cluster
from rediscluster import RedisCluster
# 定义 Redis Cluster 的启动节点
startup_nodes = [
{"host": "10.0.0.40", "port": 6379},
{"host": "10.0.0.41", "port": 6379},
{"host": "10.0.0.42", "port": 6379},
{"host": "10.0.0.43", "port": 6379},
{"host": "10.0.0.44", "port": 6379},
{"host": "10.0.0.45", "port": 6379}
]
# 创建 RedisCluster 连接
redis_conn = RedisCluster(startup_nodes=startup_nodes, password='123456', decode_responses=True)
# 批量插入并获取键值对
for i in range(0, 10000):
key = 'key' + str(i)
value = 'value' + str(i)
redis_conn.set(key, value) # 设置键值
print(f'{key}: {redis_conn.get(key)}') # 输出键值对
13.cluster和--cluster
下面这两条命令虽然都跟 Redis Cluster 相关,但它们代表了两套不同的命令体系,用途和选项也不尽相同。可以简单地理解为:
redis-cli cluster help
——服务端层面的 Cluster 子命令。这些子命令本质上是向 Redis 服务端发送CLUSTER <subcommand>命令,由 Redis 服务端执行,帮助我们在Redis 实例内部完成各种操作(例如查看节点信息、设置 slots 等)。redis-cli --cluster help
——客户端层面的 Cluster Manager 子命令。这是 Redis 命令行工具(redis-cli)提供的一个集群管理功能,通过它可以在客户端对多个节点进行统一管理、检查、rebalance、reshard 等高层次操作,而不需要逐节点去执行相应命令。
[root@node1 ~]#redis-cli -a 123456 --cluster help
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
Cluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check <host:port> or <host> <port> - separated by either colon or space
--cluster-search-multiple-owners
info <host:port> or <host> <port> - separated by either colon or space
fix <host:port> or <host> <port> - separated by either colon or space
--cluster-search-multiple-owners
--cluster-fix-with-unreachable-masters
reshard <host:port> or <host> <port> - separated by either colon or space
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance <host:port> or <host> <port> - separated by either colon or space
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
--cluster-only-masters
--cluster-only-replicas
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-from-user <arg>
--cluster-from-pass <arg>
--cluster-from-askpass
--cluster-copy
--cluster-replace
backup host:port backup_directory
help
For check, fix, reshard, del-node, set-timeout, info, rebalance, call, import, backup you can specify the host and port of any working node in the cluster.
Cluster Manager Options:
--cluster-yes Automatic yes to cluster commands prompts
[root@node1 ~]#[root@node1 ~]#redis-cli -a 123456 cluster help
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
1) CLUSTER <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) COUNTKEYSINSLOT <slot>
3) Return the number of keys in <slot>.
4) GETKEYSINSLOT <slot> <count>
5) Return key names stored by current node in a slot.
6) INFO
7) Return information about the cluster.
8) KEYSLOT <key>
9) Return the hash slot for <key>.
10) MYID
11) Return the node id.
12) MYSHARDID
13) Return the node's shard id.
14) NODES
15) Return cluster configuration seen by node. Output format:
16) <id> <ip:port@bus-port[,hostname]> <flags> <master> <pings> <pongs> <epoch> <link> <slot> ...
17) REPLICAS <node-id>
18) Return <node-id> replicas.
19) SLOTS
20) Return information about slots range mappings. Each range is made of:
21) start, end, master and replicas IP addresses, ports and ids
22) SHARDS
23) Return information about slot range mappings and the nodes associated with them.
24) ADDSLOTS <slot> [<slot> ...]
25) Assign slots to current node.
26) ADDSLOTSRANGE <start slot> <end slot> [<start slot> <end slot> ...]
27) Assign slots which are between <start-slot> and <end-slot> to current node.
28) BUMPEPOCH
29) Advance the cluster config epoch.
30) COUNT-FAILURE-REPORTS <node-id>
31) Return number of failure reports for <node-id>.
32) DELSLOTS <slot> [<slot> ...]
33) Delete slots information from current node.
34) DELSLOTSRANGE <start slot> <end slot> [<start slot> <end slot> ...]
35) Delete slots information which are between <start-slot> and <end-slot> from current node.
36) FAILOVER [FORCE|TAKEOVER]
37) Promote current replica node to being a master.
38) FORGET <node-id>
39) Remove a node from the cluster.
40) FLUSHSLOTS
41) Delete current node own slots information.
42) MEET <ip> <port> [<bus-port>]
43) Connect nodes into a working cluster.
44) REPLICATE <node-id>
45) Configure current node as replica to <node-id>.
46) RESET [HARD|SOFT]
47) Reset current node (default: soft).
48) SET-CONFIG-EPOCH <epoch>
49) Set config epoch of current node.
50) SETSLOT <slot> (IMPORTING <node-id>|MIGRATING <node-id>|STABLE|NODE <node-id>)
51) Set slot state.
52) SAVECONFIG
53) Force saving cluster configuration on disk.
54) LINKS
55) Return information about all network links between this node and its peers.
56) Output format is an array where each array element is a map containing attributes of a link
57) HELP
58) Print this help.
一、redis-cli cluster help 及其子命令详解
当我们执行:
redis-cli -a 123456 cluster help(-a 123456 只是指定了访问 Redis 的密码,与你要执行的 CLUSTER HELP 命令本身无关)
返回的内容是 Redis 服务端对外暴露的Cluster 子命令列表,即 CLUSTER <subcommand>。下面对其进行简要说明(按照它显示的顺序):
- COUNTKEYSINSLOT
<slot>- 功能:返回指定
<slot>中包含的 key 的数量(仅当前节点存储的部分)。 - 用法示例:
CLUSTER COUNTKEYSINSLOT 1234 - 场景:当你想知道某个 slot 上有多少 key,尤其在做 reshard 之前,想先确认数据量是多少时有用。
- 功能:返回指定
- GETKEYSINSLOT
<slot><count>- 功能:返回当前节点在指定
<slot>中存储的最多<count>个 key 名。 - 用法示例:
CLUSTER GETKEYSINSLOT 1234 10 - 场景:一般配合
MIGRATE命令进行迁移时,需先找到属于某个 slot 的具体 key。
- 功能:返回当前节点在指定
- INFO
- 功能:返回集群的总体信息,包括集群状态(ok 或 fail)、当前集群配置纪元(epoch)等。
- 用法示例:
CLUSTER INFO
- KEYSLOT
<key>- 功能:计算某个 key 所对应的 hash slot 值。
- 用法示例:
CLUSTER KEYSLOT mykey - 场景:用于测试或验证某个 key 会被路由到哪个 slot。
- MYID
- 功能:返回当前 Redis 节点在集群中的 node id。
- 用法示例:
CLUSTER MYID
- MYSHARDID
- 功能:返回当前节点所在的 shard 的 ID(Redis 7.0+ 出现,内部概念类似 node id,主要用于分片标识)。
- 用法示例:
CLUSTER MYSHARDID
- NODES
- 功能:返回当前节点所看到的整个集群拓扑配置。
- 用法示例:
CLUSTER NODES - 返回格式:多行文本,每一行代表一个节点的信息,包括其 ID、IP、端口、flags、master/slave 关系等。
- REPLICAS
<node-id>- 功能:返回指定
<node-id>的所有从节点信息(相当于老版本命令SLAVES <node-id>)。 - 用法示例:
CLUSTER REPLICAS 07c37dfeb2352f2f2bae
- 功能:返回指定
- SLOTS
- 功能:以区间形式返回集群中所有 slot 的分配信息,包括每个区间有哪些节点负责。
- 用法示例:
CLUSTER SLOTS
- SHARDS
- 功能:Redis 7.0+ 新增命令,与
SLOTS类似,但会返回更详细的节点信息(按 shard 分组)。 - 用法示例:
CLUSTER SHARDS
- 功能:Redis 7.0+ 新增命令,与
- ADDSLOTS
<slot> [<slot> ...]- 功能:将指定的 slot 集合分配给当前节点。
- 用法示例:
CLUSTER ADDSLOTS 1 2 3
- ADDSLOTSRANGE
<start slot> <end slot> [<start slot> <end slot> ...]- 功能:一次性将连续区间的 slot 分配给当前节点。
- 用法示例:
CLUSTER ADDSLOTSRANGE 0 1000 1001 2000
- BUMPEPOCH
- 功能:手动让当前集群的配置纪元(epoch)+1,通常用于测试或特殊情况下触发集群新的配置更新流程。
- 用法示例:
CLUSTER BUMPEPOCH
- COUNT-FAILURE-REPORTS
<node-id>- 功能:查看有多少节点报告了指定节点的失败(故障)。
- 用法示例:
CLUSTER COUNT-FAILURE-REPORTS 07c37dfeb2352f2f2bae
- DELSLOTS
<slot> [<slot> ...]- 功能:从当前节点中删除这些 slot 的归属关系(让它处于无主状态)。
- 用法示例:
CLUSTER DELSLOTS 1 2 3
- DELSLOTSRANGE
<start slot> <end slot> [<start slot> <end slot> ...]- 功能:批量删除指定区间的 slot 归属关系。
- 用法示例:
CLUSTER DELSLOTSRANGE 0 1000 1001 2000
- FAILOVER
[FORCE|TAKEOVER]- 功能:在复制结构(主从结构)中,使当前节点从从节点晋升为主节点。
- FORCE:强制故障转移,哪怕主节点在线;TAKEOVER:更高优先级,会忽略部分检查。
- 用法示例:
CLUSTER FAILOVER FORCE
- FORGET
<node-id>- 功能:从集群信息中“遗忘”某个节点,让该节点从集群拓扑中移除。
- 用法示例:
CLUSTER FORGET 07c37dfeb2352f2f2bae
- FLUSHSLOTS
- 功能:清空当前节点对所有 slot 的归属信息,但并不会对集群其他节点的视图造成影响。
- 用法示例:
CLUSTER FLUSHSLOTS
- MEET
<ip> <port> [<bus-port>]- 功能:让当前节点尝试与指定 IP 和端口的节点建立集群握手,使其加入集群。
- 用法示例:
CLUSTER MEET 192.168.1.100 7001
- REPLICATE
<node-id>- 功能:将当前节点设置为指定节点的从节点。
- 用法示例:
CLUSTER REPLICATE 07c37dfeb2352f2f2bae
- RESET
[HARD|SOFT]- 功能:重置当前节点的集群状态。
- SOFT:保留部分集群信息,只删除 slots 等。
- HARD:彻底重置,清除所有集群相关信息。
- 用法示例:
CLUSTER RESET HARD
- SET-CONFIG-EPOCH
<epoch>- 功能:手动设置当前节点的配置纪元值。
- 用法示例:
CLUSTER SET-CONFIG-EPOCH 99
- SETSLOT
<slot>(IMPORTING <node-id> | MIGRATING <node-id> | STABLE | NODE <node-id>)- 功能:设置指定 slot 的状态,例如标记为迁入中、迁出中,或指定新的归属节点等。
- 用法示例:
CLUSTER SETSLOT 1234 MIGRATING 07c37dfeb2352f2f2bae
- SAVECONFIG
- 功能:强制保存集群配置到本地磁盘(通常是
nodes.conf文件)。 - 用法示例:
CLUSTER SAVECONFIG
- 功能:强制保存集群配置到本地磁盘(通常是
- LINKS
- 功能:查看当前节点与其他节点之间的网络连接详细信息。
- 用法示例:
CLUSTER LINKS
- HELP
- 功能:打印出所有可用的
CLUSTER <subcommand>命令说明。
- 功能:打印出所有可用的
小结:
cluster help列出的这些命令都属于服务端内置的子命令,它们是针对当前连接的这个 Redis 节点,来查看或操作集群信息的。比如ADDSLOTS/DELSLOTS就是告诉“当前节点”去声明或释放某些 slots 的归属。
二、redis-cli --cluster help 及其子命令详解
当我们执行:
redis-cli -a 123456 --cluster help同样会出现一系列“Cluster Manager”命令。这些命令并不是简单的 CLUSTER <subcommand>,而是Redis CLI 工具对集群管理封装的一套功能。它会在客户端跑一些逻辑,然后对多个节点发送相应的 Redis 命令,从而帮我们完成创建集群、检查或修复集群等高级操作。
常见的子命令如下:
-
create
host1:port1 ... hostN:portN-
功能:在给定的若干 Redis 实例之间创建一个新的集群,并进行 slot 分配。
-
常见选项:
--cluster-replicas <arg>:指定每个主节点分配多少从节点。
-
用法示例:
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 \ --cluster-replicas 1
-
-
check
<host:port>- 功能:检查指定节点所在的集群是否存在配置或数据异常,例如 slot 冲突、主从同步异常等。
- 可选:
--cluster-search-multiple-owners:当存在多个节点同时持有相同 slot 时,尝试自动检测并显示。
-
info
<host:port>- 功能:显示指定节点所在集群的整体信息,包括主从节点分布、slot 分配、可能的问题等。
- 用法示例:
redis-cli --cluster info 127.0.0.1:7001
-
fix
<host:port>- 功能:针对检查出的问题尝试进行修复,比如修正 slot 的 owner、清理不正确的配置等。
- 常见选项:
--cluster-search-multiple-owners:检测并尝试修复多个节点同时拥有同一 slot 的冲突问题。--cluster-fix-with-unreachable-masters:即使主节点无法访问,也要尝试进行修复。
- 用法示例:
redis-cli --cluster fix 127.0.0.1:7001 --cluster-search-multiple-owners
-
reshard
<host:port>-
功能:对集群中的 slot 进行重新分配(手动或交互式),实现数据在各节点之间重新均衡。
-
常见选项:
--cluster-from <node id>:指定从哪个节点或节点集合中抽取 slot。--cluster-to <node id>:指定 slot 将迁移到哪个节点。--cluster-slots <个数>:要迁移多少个 slot。--cluster-yes:自动确认(不再提示交互)。--cluster-timeout <arg>:迁移超时设置。--cluster-pipeline <arg>:迁移时使用 pipeline 发送多少个 key。--cluster-replace:若目标节点已拥有该 slot 的信息,也强行替换。
-
用法示例:
redis-cli --cluster reshard 127.0.0.1:7001 \ --cluster-from 07c37dfeb2352f2f2bae \ --cluster-to 09a49dfeb2352f2f2cde \ --cluster-slots 100 \ --cluster-yes
-
-
rebalance
<host:port>- 功能:在集群中执行自动负载均衡,让各节点的 slot 数量大体趋于平均。
- 常见选项:
--cluster-weight <node1=w1...nodeN=wN>:给节点设置“权重”,使 rebalance 时并非绝对平均,而是按权重分配 slot。--cluster-use-empty-masters:在 rebalance 时也会考虑那些目前没有 slots 的主节点。--cluster-timeout <arg>:操作超时。--cluster-simulate:只模拟操作,并不真正执行。--cluster-pipeline <arg>:迁移 key 时的 pipeline 大小。--cluster-threshold <arg>:只有当节点 slot 数差异超过一定阈值才进行迁移。--cluster-replace:迁移中如遇 slot 冲突允许替换。
- 用法示例:
redis-cli --cluster rebalance 127.0.0.1:7001 --cluster-use-empty-masters --cluster-yes
-
add-node
new_host:new_port existing_host:existing_port-
功能:向已经在运行的集群中新增加一个节点(可以指定是作为从节点,或者让它自己成为主节点)。
-
常见选项:
--cluster-slave:以从节点的角色加入集群。--cluster-master-id <arg>:如果要作为从节点,指明它的主节点 ID。
-
用法示例:
redis-cli --cluster add-node 192.168.1.100:7004 192.168.1.100:7001 \ --cluster-slave \ --cluster-master-id 07c37dfeb2352f2f2bae
-
-
del-node
host:port node_id- 功能:从集群拓扑中删除指定 node_id 的节点。
- 用法示例:
redis-cli --cluster del-node 127.0.0.1:7001 07c37dfeb2352f2f2bae
-
call
host:port command arg arg .. arg- 功能:对集群的所有节点(或只对主节点/从节点)执行一个自定义命令。
- 常见选项:
--cluster-only-masters:只对主节点执行。--cluster-only-replicas:只对从节点执行。
- 用法示例:
redis-cli --cluster call 127.0.0.1:7001 CONFIG GET maxmemory --cluster-only-masters
-
set-timeout
host:port milliseconds- 功能:设置集群节点的
cluster-node-timeout参数。 - 用法示例:
redis-cli --cluster set-timeout 127.0.0.1:7001 2000
- 功能:设置集群节点的
-
import
host:port-
功能:将单节点 Redis 的数据导入到指定的集群节点中。
-
常见选项:
--cluster-from <arg>:源 Redis 的地址。--cluster-from-user <arg>/--cluster-from-pass <arg>/--cluster-from-askpass:指定源 Redis 的认证方式。--cluster-copy:复制数据而不是迁移数据。--cluster-replace:如 slot 中已有 key 是否直接覆盖。
-
用法示例:
redis-cli --cluster import 127.0.0.1:7001 \ --cluster-from 127.0.0.1:6379 \ --cluster-from-pass 123456 \ --cluster-copy \ --cluster-replace
-
-
backup
host:port backup_directory- 功能:从集群中每个节点获取 RDB 快照并保存到本地指定目录,做集群级的统一备份。
- 用法示例:
redis-cli --cluster backup 127.0.0.1:7001 /data/redis_backups/
-
help
- 功能:打印出以上 Cluster Manager 命令的帮助信息。
小结:
--cluster模式下的命令可以看作是一个“批处理管理工具”,它会自动遍历或连接集群中多个节点执行相应操作(创建、检查、修复、分片迁移等),简化了人工逐个节点执行命令的麻烦。
三、两者的主要区别与使用场景
- 作用层次不同
cluster help:侧重于服务端提供的低层次操作接口,直接通过CLUSTER <subcommand>与 Redis 节点交互。--cluster help:侧重于客户端的集群管理脚本功能,相当于在本地批量调用若干 Redis 命令来完成更复杂的集群管理操作。
- 使用场景不同
cluster help:常用于日常运维或在线查看集群状态、slot 信息,或在做某些手动精细化操作(比如精确地给节点添加 slot、指定迁移 slot 状态)时使用。--cluster help:常用于一键式操作,比如:- 创建集群(
create) - 自动均衡(
rebalance) - 重分片(
reshard) - 检查/修复(
check/fix) - 备份(
backup)
- 创建集群(
- 选项涵盖面
cluster help:Redis 服务端自带,子命令相对固定,围绕 slot 与节点元信息进行管理。--cluster help:Redis CLI 扩展,提供了更多“综合管理”选项(如一次性在多个节点执行命令、自动处理交互、自动计算 slot 分配等)。
总结
redis-cli cluster help展示的是 Redis 服务端自身支持的CLUSTER子命令,适合对集群进行细粒度、内置命令级的操作或查询。redis-cli --cluster help则是 Redis CLI 工具提供的高级管理命令集合,让我们在客户端就能对整个集群进行一站式的部署、检查、修复、迁移、备份等操作。
在实际运维中,两者经常是结合使用的:当需要快速创建或重分片时,用 --cluster;当需要深入到某个具体节点查看或调整 slot 时,就使用 CLUSTER <subcommand>。两种方式熟练掌握,可以大大提升对 Redis Cluster 的管理效率和灵活度。
14.Redis cluster集群动态扩容
因公司业务发展迅猛,现有的三主三从的redis cluster架构可能无法满足现有业务的并发写入需求,因此公司紧急采购两台服务器10.0.0.46,10.0.0.47,需要将其动态添加到集群当中,但不能影响业务使用和数据丢失。
注意:生产环境一般建议master节点为奇数个,防止脑裂现象。
14.1 添加新的master节点到集群
# 首先安装redis,再执行下面命令
[root@Rocky9 ~]# sed -i.bak -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e '/masterauth/a masterauth 123456' -e '/# requirepass/a requirepass 123456' -e '/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-require-full-coverage yes/c cluster-require-full-coverage no' /apps/redis/etc/redis.conf
[root@Rocky9 ~]# systemctl restart redis
[root@Rocky9 ~]# ps aux | grep redis
redis 19937 0.3 0.8 136680 8192 ? Ssl 16:57 0:00 /apps/redis/bin/redis-server 0.0.0.0:6379 [cluster]
root 19947 0.0 0.2 6408 2048 pts/0 S+ 16:57 0:00 grep --color=auto redis
# 46加入到40所在的集群节点
[root@Rocky9 ~]# redis-cli -a 123456 --cluster add-node 10.0.0.46:6379 10.0.0.40:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 10.0.0.46:6379 to cluster 10.0.0.40:6379
>>> Performing Cluster Check (using node 10.0.0.40:6379)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots: (0 slots) slave
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Send FUNCTION LIST to 10.0.0.46:6379 to verify there is no functions in it
>>> Send FUNCTION RESTORE to 10.0.0.46:6379
>>> Send CLUSTER MEET to node 10.0.0.46:6379 to make it join the cluster.
[OK] New node added correctly.
# 查看集群节点,46加入了集群节点,并成为master
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1736953737000 3 connected 10923-16383
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1736953737211 7 connected 0-5460
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736953736201 3 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736953736000 2 connected 5461-10922
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1736953738220 0 connected
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736953736000 2 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 7 connected14.2 在新的master上重新分配槽位
新的node节点加入到集群之后,默认是master节点,但是没有slots,需要重新分配。添加主机之后需要对添加至集群中的新主机重新分片,否则其他没有分片也就无法写入数据。
注意:重新分配槽位需要清空数据,所以需要先备份数据,扩容后再恢复数据。
# 方法1:手动分配槽(Slots),40是当前任意节点即可(40-45)
[root@Rocky9 ~]# redis-cli -a 123456 --cluster reshard 10.0.0.40:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 10.0.0.40:6379)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[0-1364],[12287-16383] (5462 slots) master
1 additional replica(s)
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[1365-6825] (5461 slots) master
1 additional replica(s)
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[6826-12286] (5461 slots) master
1 additional replica(s)
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379 #新加入的master节点已经列出来了
slots: (0 slots) master
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots: (0 slots) slave
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 要迁移多少个槽
How many slots do you want to move (from 1 to 16384)? 4096 #新分配多少个槽位=16384/master个数
# 槽的目标节点
What is the receiving node ID? c882647e71c8f3cc1b40ea20cc242fecca371cd4 #输入接收的master的ID(这里就是46这台机器的ID)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all #将哪些源主机的槽位分配给新节点,all是自动在所有的redis node选择划分,如果是从redis cluster删除某个主机可以使用此方式将指定主机上的槽位全部移动到别的redis主机上
Ready to move 4096 slots.
Source nodes: #槽的来源节点,从下面三个master上移动槽位给46
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[0-1364],[12287-16383] (5462 slots) master
1 additional replica(s)
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[1365-6825] (5461 slots) master
1 additional replica(s)
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[6826-12286] (5461 slots) master
1 additional replica(s)
Destination node: #槽的目标节点
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots: (0 slots) master
Resharding plan:
Moving slot 0 from 767c6fc628516c09dd63fe4dbdc36cecee3808b3
Moving slot 1 from 767c6fc628516c09dd63fe4dbdc36cecee3808b3
...... #这里省略类似信息
Moving slot 8190 from c9b13ad218d3c8aaf62153738bb21d08a59a66c8
Do you want to proceed with the proposed reshard plan (yes/no)? yes #确认分配
......
Moving slot 8189 from 10.0.0.41:6379 to 10.0.0.46:6379: .
Moving slot 8190 from 10.0.0.41:6379 to 10.0.0.46:6379: .
# 方法2:通过rebalance进行自动分配,不需要计算要分配的槽位(下面会重点讲解这两个命令的区别reshard和rebalance)
[root@Rocky9 ~]# redis-cli -a 123456 --cluster rebalance 10.0.0.40:6379 --cluster-use-empty-masters
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 10.0.0.40:6379)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Rebalancing across 4 nodes. Total weight = 4.00
Moving 1366 slots from 10.0.0.41:6379 to 10.0.0.46:6379 #从41上移动了1366个slots
###################################################################################################################################################################
......
Moving 1365 slots from 10.0.0.44:6379 to 10.0.0.46:6379 # 从44上移动了1365个slots
###################################################################################################################################################################
......
Moving 1365 slots from 10.0.0.42:6379 to 10.0.0.46:6379 #从42上移动了1365个slots
###################################################################################################################################################################
......
[root@Rocky9 ~]#
# 查看集群节点分配情况
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1736992172987 12 connected 12288-16383
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1736992170964 10 connected 2730-6825
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736992171000 12 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736992169957 11 connected 8191-12286
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1736992172000 13 connected 0-2729 6826-8190 12287 #槽位已经分配好了
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736992168000 11 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 10 connected
[root@node1 ~]#
# 只查看槽位分配情况
[root@node1 ~]#redis-cli -a 123456 --cluster check 10.0.0.46:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.46:6379 (c882647e...) -> 2506 keys | 4096 slots | 0 slaves. #4096个slots
10.0.0.44:6379 (5023eb92...) -> 2494 keys | 4096 slots | 1 slaves.
10.0.0.42:6379 (767c6fc6...) -> 2500 keys | 4096 slots | 1 slaves.
10.0.0.41:6379 (c9b13ad2...) -> 2500 keys | 4096 slots | 1 slaves.
[OK] 10000 keys in 4 masters.
0.61 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.46:6379)
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots:[0-2729],[6826-8190],[12287] (4096 slots) master
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[2730-6825] (4096 slots) master
1 additional replica(s)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[8191-12286] (4096 slots) master
1 additional replica(s)
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots: (0 slots) slave
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@node1 ~]#reshard和rebalance区别:
在 Redis Cluster 中,reshard 和 rebalance 都可以实现对槽(slots)的重新分配,但二者在使用场景和操作方式上有所区别:
- reshard
- 命令:
redis-cli --cluster reshard <host>:<port> - 定位:手动指定要从哪些节点(源节点)移动多少个槽到目标节点。
- 典型场景:
- 当你想精细地控制某些节点的槽分配时,比如把部分槽从节点 A 精准地移动到节点 B,而其他节点不受影响。
- 有些场景想只给某个新节点分配指定范围或数量的槽,而无需动到整个集群的槽分布。
- 操作方式:在交互式命令行中会让你选择:
- 移动多少个槽;
- 从哪些节点搬出槽;
- 把这些槽搬到哪个节点。
然后 Redis CLI 会一步步执行迁移并进行数据复制。
- 命令:
- rebalance
- 命令:
redis-cli --cluster rebalance <host>:<port> - 定位:自动在所有主节点之间重新平衡槽的分配,使槽尽量平均地分布在各个节点。
- 典型场景:
- 当新加入一个主节点,希望自动把集群里的槽分担一部分给它,让槽(以及数据)在所有主节点之间尽量平均。
- 或者有些主节点负载过重,自动让脚本来做“平均化”处理,而无需手动挑选要移动多少槽、从哪个节点移动到哪个节点。
- 操作方式:一条命令,Redis 会扫描所有主节点的槽占用情况,尝试让每个节点大致拥有同样数量的槽,并执行槽迁移和数据复制。
- 命令:
二者的主要区别
- 操作的灵活度
- reshard:更加“手动”,可以精细化指定源节点和目标节点,以及槽的数量或范围。适合需要对槽迁移进行自定义控制的场景。
- rebalance:更加“自动”,Redis 自己计算出如何把槽分配得更均匀。适合大多数快速均衡场景。
- 使用难易程度
- reshard:需要你逐步确认哪些节点要移动多少槽,操作繁琐但灵活度高。
- rebalance:一键式自动均衡,简单快捷,但不能过多自定义移动细节。
- 应用场景
- reshard:
- 精确控制某些节点的负载;
- 只想调整部分节点,而不希望影响到其他节点。
- rebalance:
- 新加主节点后,让整个集群自动均衡槽分布;
- 集群某些主节点负载严重不均衡,希望一键平衡。
- reshard:
总结:
- reshard:更适合精细化、指定范围或单一节点的槽转移场景。
- rebalance:更适合全局、自动化的槽再平衡场景。
在实际生产中,如果只是单纯要让新节点上线并分担部分流量,通常用
rebalance就够了;如果需要对槽分配高度自定义,则可使用reshard。
14.3 为新的master添加新的slave节点
需要再向当前Redis集群中添加一个Redis单机服务器10.0.0.47,用于解决当前10.0.0.46单机的潜在宕机问题,即实现响应的高可用问题,有两种方式:
方法1:在新节点添加到集群时,直接将之设置为slave
# 直接加为slave节点<10.0.0.47>是加入的slave节点,<10.0.0.46>是加入到的集群任意一个节点
[root@node1 ~]#redis-cli -a 123456 --cluster add-node 10.0.0.47:6379 10.0.0.46:6379 --cluster-slave --cluster-master-id c882647e71c8f3cc1b40ea20cc242fecca371cd4
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 10.0.0.47:6379 to cluster 10.0.0.46:6379
>>> Performing Cluster Check (using node 10.0.0.46:6379)
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots: (0 slots) slave
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 10.0.0.47:6379 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 10.0.0.46:6379.
[OK] New node added correctly.
# 验证是否成功
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1736954647000 3 connected 12288-16383
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 slave c882647e71c8f3cc1b40ea20cc242fecca371cd4 0 1736954647000 8 connected #47成为了46的slave
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1736954646000 7 connected 1365-5460
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736954648000 3 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736954648253 2 connected 6827-10922
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1736954649263 8 connected 0-1364 5461-6826 10923-12287
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736954646000 2 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 7 connectedmeet和add-node的区别:
redis-cli --cluster add-node <new_node_host:port> <existing_node_host:port>它其实会在内部帮你完成原生的 CLUSTER MEET <ip> <port> 操作,并且还会做一些额外的检查和提示(比如版本兼容、集群状态等)。也就是说:
redis-cli --cluster add-node ...是一个更“高级”的封装,一条命令即可把新节点加入集群。CLUSTER MEET <ip> <port>是 Redis Cluster 原生底层命令,属于纯手动操作方式。
二者本质上都能让新节点与现有集群“握手”,最终效果相同。只不过,--cluster add-node 更适合对新手或追求自动化的用户,而手动 CLUSTER MEET 方式更加原始、灵活。一般来说:
- 使用
--cluster add-node- 需要的命令更少,更自动化。
- 如果后面还需要自动分配槽(slots),还可以直接配合
--cluster rebalance等子命令。
- 使用
CLUSTER MEET- 需要对 Redis Cluster 有一定了解。
- 可以配合
cluster replicate <node_id>或cluster addslots等手工方式一步步细粒度地操作。
因此,你在命令行中看到的是:
redis-cli -a 123456 --cluster add-node 10.0.0.46:6379 10.0.0.40:6379而不是手动执行:
redis-cli -h 10.0.0.40 -p 6379 -a 123456 cluster meet 10.0.0.46 6379方法2:先将新节点加入集群,在修改为slave
为新的master添加slave节点
# 把10.0.0.47:6379添加到集群中
[root@Rocky9 ~]# redis-cli -a 123456 --cluster add-node 10.0.0.47:6379 10.0.0.46:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 10.0.0.47:6379 to cluster 10.0.0.46:6379
>>> Performing Cluster Check (using node 10.0.0.46:6379)
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots:[0-2729],[6826-8190],[12287] (4096 slots) master
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[2730-6825] (4096 slots) master
1 additional replica(s)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots:[8191-12286] (4096 slots) master
1 additional replica(s)
S: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots: (0 slots) slave
replicates c9b13ad218d3c8aaf62153738bb21d08a59a66c8
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Send FUNCTION LIST to 10.0.0.47:6379 to verify there is no functions in it
>>> Send FUNCTION RESTORE to 10.0.0.47:6379
>>> Send CLUSTER MEET to node 10.0.0.47:6379 to make it join the cluster.
[OK] New node added correctly.
[root@Rocky9 ~]#
# 查看当前集群节点
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1736998066832 12 connected 12288-16383
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 master - 0 1736998065000 0 connected #47已经加入了,但是角色是master
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1736998064814 10 connected 2730-6825
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736998066000 12 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736998067843 11 connected 8191-12286
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1736998065000 13 connected 0-2729 6826-8190 12287
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736998066000 11 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 10 connected
[root@node1 ~]#
更改新节点状态为slave:
需要手动将其指定为某个master的slave,否则其默认角色为master。
redis-cli -h <新节点IP> -p <新节点端口> \
cluster replicate <目标主节点ID>[root@Rocky9 ~]# redis-cli -a 123456 -h 10.0.0.47 -p 6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.47:6379> CLUSTER NODES
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736998213000 11 connected
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1736998213000 13 connected 0-2729 6826-8190 12287
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736998214000 12 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 slave 5023eb920093b0da73426572ef189d98f337023e 0 1736998216178 10 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736998215167 11 connected 8191-12286
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 myself,master - 0 0 0 connected # master
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1736998214000 12 connected 12288-16383
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1736998214156 10 connected 2730-6825
10.0.0.47:6379> CLUSTER REPLICATE c882647e71c8f3cc1b40ea20cc242fecca371cd4 #将其设为slave,命令格式 cluster replicate MASTERID
OK
10.0.0.47:6379> CLUSTER NODES
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 slave c9b13ad218d3c8aaf62153738bb21d08a59a66c8 0 1736998293993 11 connected
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1736998291000 13 connected 0-2729 6826-8190 12287
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1736998294000 12 connected
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 slave 5023eb920093b0da73426572ef189d98f337023e 0 1736998291000 10 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 master - 0 1736998295006 11 connected 8191-12286
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 myself,slave c882647e71c8f3cc1b40ea20cc242fecca371cd4 0 0 13 connected # 是46的slave
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1736998293000 12 connected 12288-16383
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1736998292982 10 connected 2730-6825
10.0.0.47:6379>15.Redis cluster集群动态缩容
实战案例:
由于10.0.0.46服务器使用年限已经超过三年,已经超过厂商质保期而且硬盘出现异常报警,经运维部架构师提交方案并同开发同事开会商议,决定将现有Redis集群的8台主服务器中的master 10.0.0.46和对应的slave 10.0.0.47 临时下线,三台服务器的并发写入性能足够支出未来1-2年的业务需求。
删除节点过程:
添加节点的时候是先添加node节点到集群,然后分配槽位,删除节点的操作与添加节点的操作正好相反,是先将被删除的Redis node上的槽位迁移到集群中的其他Redis node节点上,然后再将其删除,如果一个Redis node节点上的槽位没有完全被迁移,删除该node的时候会提示有数据且无法删除。
在 Redis Cluster 中,如果打算缩容(移除一个主节点),需要先把该节点上所有槽 (slots) 和数据迁移到其它主节点,然后再执行删除操作。
15.1 迁移master的槽位至其他master节点
方法1:手动迁移
# 查看集群节点
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1737090417358 12 connected 12288-16383
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 slave c882647e71c8f3cc1b40ea20cc242fecca371cd4 0 1737090416000 13 connected #要删除的slave节点
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1737090415000 10 connected 2730-6825
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1737090416346 12 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 slave 637a013fee8c69a87d4ca9d503f01d3817680f4c 0 1737090418370 14 connected
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 master - 0 1737090414000 13 connected 0-2729 6826-8190 12287 #要删除的master节点
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 master - 0 1737090416000 14 connected 8191-12286
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 10 connected
# 查看当前状态
[root@Rocky9 ~]# redis-cli -a 123456 --cluster check 10.0.0.46:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.46:6379 (c882647e...) -> 2506 keys | 4096 slots | 1 slaves.
10.0.0.44:6379 (5023eb92...) -> 2494 keys | 4096 slots | 1 slaves.
10.0.0.42:6379 (767c6fc6...) -> 2500 keys | 4096 slots | 1 slaves.
10.0.0.45:6379 (637a013f...) -> 2500 keys | 4096 slots | 1 slaves.
[OK] 10000 keys in 4 masters.
0.61 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.46:6379)
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots:[0-2729],[6826-8190],[12287] (4096 slots) master # 46master节点slot的范围
1 additional replica(s)
S: 8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379
slots: (0 slots) slave
replicates c882647e71c8f3cc1b40ea20cc242fecca371cd4
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[2730-6825] (4096 slots) master
1 additional replica(s)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
S: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots: (0 slots) slave
replicates 637a013fee8c69a87d4ca9d503f01d3817680f4c
M: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots:[8191-12286] (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 连接到任意集群节点,4096/3=1365(约等于)平均每个节点应该分配1365个槽位
# 1.将1365个slot从10.0.0.46移动到10.0.0.44上(这样移动的原因是44的槽位是从[2730-6825],而46的第一部分槽位是从[0-2729],所以这样就连续住了)
[root@Rocky9 ~]# redis-cli -a 123456 --cluster reshard 10.0.0.46:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 10.0.0.46:6379)
# 分片之前会自动检查当前集群的节点信息(包括槽位的区间,node id,槽位的个数,slave对应master)
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots:[0-2729],[6826-8190],[12287] (4096 slots) master
1 additional replica(s)
S: 8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379
slots: (0 slots) slave
replicates c882647e71c8f3cc1b40ea20cc242fecca371cd4
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[2730-6825] (4096 slots) master
1 additional replica(s)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
S: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots: (0 slots) slave
replicates 637a013fee8c69a87d4ca9d503f01d3817680f4c
M: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots:[8191-12286] (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365 #本次要迁移槽位的个数
What is the receiving node ID? 5023eb920093b0da73426572ef189d98f337023e #接收槽位的主节点的id
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: c882647e71c8f3cc1b40ea20cc242fecca371cd4 #源主节点的id
Source node #2: done #输入done
Ready to move 1365 slots.
Source nodes:
M: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots:[0-2729],[6826-8190],[12287] (4096 slots) master
1 additional replica(s)
Destination node:
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[2730-6825] (4096 slots) master
1 additional replica(s)
Resharding plan:
Moving slot 0 from c882647e71c8f3cc1b40ea20cc242fecca371cd4
......
Moving slot 1364 from c882647e71c8f3cc1b40ea20cc242fecca371cd4
Do you want to proceed with the proposed reshard plan (yes/no)?yes #输入yes
Moving slot 0 from 10.0.0.46:6379 to 10.0.0.44:6379: ..
......
Moving slot 1364 from 10.0.0.46:6379 to 10.0.0.44:6379:
#非交互的方式
#再将1365个slot从10.0.0.46移动到第二个master节点10.0.0.45上
[root@Rocky9 ~]# redis-cli -a 123456 --cluster reshard 10.0.0.46:6379 --cluster-slots 1365 --cluster-from c882647e71c8f3cc1b40ea20cc242fecca371cd4 --cluster-to 637a013fee8c69a87d4ca9d503f01d3817680f4c --cluster-yes
# 最后的slot从10.0.0.46移动到第三个master节点10.0.0.42上
[root@Rocky9 ~]#redis-cli -a 123456 --cluster reshard 10.0.0.46:6379 --cluster-slots 1366 --cluster-from c882647e71c8f3cc1b40ea20cc242fecca371cd4 --cluster-to 767c6fc628516c09dd63fe4dbdc36cecee3808b3 --cluster-yes
#确认10.0.0.46的所有slot都移走了,并且在7系列版本中master自动会变成slave,并且之前它的slave,一起变成其他master的slave
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1737093990000 17 connected 6826-8190 12287-16383
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1737093990641 17 connected #自动切换成42的slave
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1737093991650 15 connected 0-1364 2730-6825
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1737093992660 17 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 slave 637a013fee8c69a87d4ca9d503f01d3817680f4c 0 1737093989000 16 connected
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1737093991000 17 connected #切换成42的slave
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 master - 0 1737093991000 16 connected 1365-2729 8191-12286
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 15 connected
[root@node1 ~]#redis-cli -a 123456 --cluster check 10.0.0.40:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.42:6379 (767c6fc6...) -> 3345 keys | 5462 slots | 3 slaves.
10.0.0.44:6379 (5023eb92...) -> 3314 keys | 5461 slots | 1 slaves.
10.0.0.45:6379 (637a013f...) -> 3341 keys | 5461 slots | 1 slaves.
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.40:6379)
S: 334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379
slots: (0 slots) slave
replicates 5023eb920093b0da73426572ef189d98f337023e
M: 767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379
slots:[6826-8190],[12287-16383] (5462 slots) master
3 additional replica(s)
S: 8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379
slots:[0-1364],[2730-6825] (5461 slots) master
1 additional replica(s)
S: 12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
S: c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379
slots: (0 slots) slave
replicates 637a013fee8c69a87d4ca9d503f01d3817680f4c
S: c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379
slots: (0 slots) slave
replicates 767c6fc628516c09dd63fe4dbdc36cecee3808b3
M: 637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379
slots:[1365-2729],[8191-12286] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 查看42的主从复制情况,有三个slave
[root@node1 ~]#redis-cli -a 123456 -h 10.0.0.42 info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:master
connected_slaves:3
slave0:ip=10.0.0.43,port=6379,state=online,offset=488319,lag=0
slave1:ip=10.0.0.46,port=6379,state=online,offset=488319,lag=0
slave2:ip=10.0.0.47,port=6379,state=online,offset=488319,lag=1
master_failover_state:no-failover
master_replid:b4e315107bb91caf6f49e76488cf53329f776ab5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:488319
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:488319
[root@node1 ~]#
# 查看集群情况
[root@node1 ~]#redis-cli -a 123456 -h 10.0.0.40 --no-auth-warning cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:8
cluster_size:3 #有3个主节点
cluster_current_epoch:17
cluster_my_epoch:15
cluster_stats_messages_ping_sent:135374
cluster_stats_messages_pong_sent:128159
cluster_stats_messages_fail_sent:7
cluster_stats_messages_update_sent:2
cluster_stats_messages_sent:263542
cluster_stats_messages_ping_received:128157
cluster_stats_messages_pong_received:151740
cluster_stats_messages_meet_received:2
cluster_stats_messages_fail_received:2
cluster_stats_messages_auth-req_received:1
cluster_stats_messages_update_received:1
cluster_stats_messages_received:279903
total_cluster_links_buffer_limit_exceeded:0
[root@node1 ~]#方法2:自动迁移
[root@Rocky9 ~]# redis-cli -a 123456 --cluster rebalance 10.0.0.40:6379 --cluster-weight c882647e71c8f3cc1b40ea20cc242fecca371cd4=0 --cluster-use-empty-masters
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 10.0.0.40:6379)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Rebalancing across 4 nodes. Total weight = 3.00
Moving 1366 slots from 10.0.0.46:6379 to 10.0.0.42:6379
###################################################################################################################################################################
......
Moving 1365 slots from 10.0.0.46:6379 to 10.0.0.44:6379
###################################################################################################################################################################
......
Moving 1365 slots from 10.0.0.46:6379 to 10.0.0.45:6379
###################################################################################################################################################################
......
[root@Rocky9 ~]# redis-cli -a 123456 -h 10.0.0.40 -p 6379 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1737105281417 19 connected 0-1365 12288-16383
8b4c349f957e7166dc2834cc1f7109d73ee25542 10.0.0.47:6379@16379 slave 637a013fee8c69a87d4ca9d503f01d3817680f4c 0 1737105278000 21 connected
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1737105277383 20 connected 1366-6826
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1737105279000 19 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 slave 637a013fee8c69a87d4ca9d503f01d3817680f4c 0 1737105280000 21 connected
c882647e71c8f3cc1b40ea20cc242fecca371cd4 10.0.0.46:6379@16379 slave 637a013fee8c69a87d4ca9d503f01d3817680f4c 0 1737105280409 21 connected
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 master - 0 1737105278000 21 connected 6827-12287
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 20 connected
[root@Rocky9 ~]#--cluster-weight <NodeID>=0 :将节点的权重设为 0,表示不要给它分配槽,并把它目前所有槽都迁走。
--cluster-use-empty-masters :允许将新的空节点或指定节点也被纳入 rebalance 的考量之中。
在 rebalance 过程中,Redis 会把该节点上的全部槽迁移到其他主节点上(取决于当前集群状态,可能会平均迁移到多个节点)。
15.2 从集群删除节点
虽然槽位已经迁移完成了,但是服务器IP信息还在集群当中,因此还需要将IP信息从集群中删除
注意:删除服务器前,必须清除主机上面的槽位,否则会删除失败。
# redis-cli -a 123456 --cluster del-node 10.0.0.40:6379 <NodeID_of_46>
[root@Rocky9 ~]# redis-cli -a 123456 --cluster del-node 10.0.0.46:6379 c882647e71c8f3cc1b40ea20cc242fecca371cd4
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node c882647e71c8f3cc1b40ea20cc242fecca371cd4 from cluster 10.0.0.46:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.15.3 删除多余的slave节点
[root@Rocky9 ~]# redis-cli -a 123456 --cluster del-node 10.0.0.47:6379 8b4c349f957e7166dc2834cc1f7109d73ee25542
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node 8b4c349f957e7166dc2834cc1f7109d73ee25542 from cluster 10.0.0.47:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
# 查看集群节点(46和47都没有了)
[root@node1 ~]#redis-cli -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
767c6fc628516c09dd63fe4dbdc36cecee3808b3 10.0.0.42:6379@16379 master - 0 1737101127000 17 connected 6826-8190 12287-16383
5023eb920093b0da73426572ef189d98f337023e 10.0.0.44:6379@16379 master - 0 1737101128171 15 connected 0-1364 2730-6825
12b6dbf4fd222db57a57e0bbd42694377a107ca5 10.0.0.43:6379@16379 slave 767c6fc628516c09dd63fe4dbdc36cecee3808b3 0 1737101127159 17 connected
c9b13ad218d3c8aaf62153738bb21d08a59a66c8 10.0.0.41:6379@16379 slave 637a013fee8c69a87d4ca9d503f01d3817680f4c 0 1737101127000 16 connected
637a013fee8c69a87d4ca9d503f01d3817680f4c 10.0.0.45:6379@16379 master - 0 1737101125139 16 connected 1365-2729 8191-12286
334ecb1234284cfa2a60ced7c5a8d29f4cd5de10 10.0.0.40:6379@16379 myself,slave 5023eb920093b0da73426572ef189d98f337023e 0 0 15 connected
[root@node1 ~]#16.导入数据到Cluster中
在 Redis Cluster 多主节点的环境下,无法简单地把“一份 RDB 文件”直接拷贝到所有节点的目录下就完成数据导入。因为 Redis Cluster 是基于 哈希槽 (hash slots) 进行分片管理,各个主节点分别持有不同的槽及数据。如果你仅仅将一份 RDB 放到其中某个节点的本地目录,然后启动该节点,就会出现以下问题:
- RDB 文件中的数据并不一定符合该节点所负责的槽范围,会导致集群节点之间对槽的归属产生冲突;
- 其他节点上没有相应的数据,也不清楚该节点突然新增的数据对于集群整体意味着什么;
- 可能打乱原先集群中的槽配置及数据一致性。
因此,在“现有”Redis Cluster 上导入一份新的 RDB,需要一个“数据迁移”或“数据导入”的过程,让每条键值都落到正确的槽对应的节点上。下面给出几种常见的可行做法:
方法一:先在单机 Redis 中加载 RDB,再使用
redis-cli --cluster import导入这是官方提供的一种“半自动”方案,适合将单机数据导入到集群中:
- 启动一个单机 Redis
- 假设端口是 6380,把你要导入的 RDB 文件放到这个单机 Redis 的数据目录下(即
dir所在路径),确保单机 Redis 启动后能加载该 RDB,拥有完整数据。- 确认单机 Redis 数据正常
- 用
redis-cli -p 6380 dbsize或keys *(生产环境勿用KEYS *,可用SCAN) 查看是否已经成功加载目标数据。- 使用
redis-cli --cluster import
- 在你的 Redis CLI 所在机器上,执行:
redis-cli --cluster import 127.0.0.1:6380这里127.0.0.1:6380是指那台单机 Redis 的地址和端口。- 随后会进入一个交互式流程,要求你指定目标集群的信息(任意一个节点的 IP:Port),以及是否要执行真正的数据迁移。
- 完成迁移
- Redis CLI 会逐个键进行
MIGRATE或相应指令,把数据按正确的哈希槽分发到你的现有 Redis Cluster 中。- 迁移完成后,你可以关闭该单机 Redis 或者保留做备份均可。
注意:
--cluster import在不同 Redis 版本中可能略有差异,需保证redis-cli版本与服务器端兼容(Redis 5.0+ 通常支持得比较好)。一定是单机的Redis,不能是cluster,否则会报错。
方法二:使用
MIGRATE/RESTORE等命令手动脚本导入如果你想完全自己可控(或者 Redis 版本较老,没有
--cluster import),可以采取“脚本 + 命令”的方式:
- 依然先启动一台单机 Redis,加载 RDB 文件,让这台单机 Redis 拥有完整数据。
- 遍历所有键
- 通过
SCAN命令逐批获取源实例中的所有 key;- 对于每个 key,使用
CLUSTER KEYSLOT <key>算出它属于哪个槽,然后找到集群中负责该槽的节点;- 使用
MIGRATE或RESTORE/DUMP等方式,将该 key 的数据迁移到对应节点。- 脚本化批量执行
- 由于手工敲命令效率低且容易出错,通常会编写 Python、Go、Shell 等脚本完成上述逻辑。
这种方法更灵活,但开发和执行成本较高,需要自己管理批次和网络故障重试等细节。
方法三:先用这份 RDB 创建一个“单节点集群”,再扩容/合并到现有集群
如果你想保留集群模式(而不是先启动为单机),也可以新建一个临时的单节点集群来承载这份 RDB 数据,然后再将这个节点合并到现有集群,再做槽分配 (reshard/rebalance)。不过操作步骤更多,一般不如前两种方法直接。
大致流程:
- 启动一个 Redis,开启
cluster-enabled yes,让它自成一个集群(单主,无从节点),加载这份 RDB;- 用
redis-cli --cluster add-node命令把这个单节点集群“合并”进你现有的 Redis Cluster;- 再用
redis-cli --cluster rebalance或redis-cli --cluster reshard将所有槽均衡或迁移到对应节点;- 最终可以选择保留或删除该“临时节点”,看你实际需求而定。
这种方式在一些特定情况下会比较方便,例如你不想先运行“纯单机”,而希望保持所有节点都在“集群模式”。但是要特别注意它与原集群的 cluster config 配置以及节点间 meet、握手 的兼容问题。
小结
- 不能直接把 RDB 文件拷到某个已在集群内的节点目录下并重启,就让集群“自动拥有”这份数据——Redis Cluster 并不会自动识别并分片这些新数据。
- 最佳实践通常是:
- 启动一个“独立 Redis”加载 RDB;
- 使用
--cluster import或者手动MIGRATE将数据写入你的目标 Redis Cluster;- 验证数据完整性和业务可用后,关闭或保留该独立实例。
这样做既可在最小风险下完成数据导入,又不至于打乱现有集群的哈希槽分配。
# 取消所有机器的密码
[root@node1 ~]#redis-cli -a 123456 config set requirepass ""
# 取消保护模式
[root@node1 ~]#redis-cli CONFIG SET protected-mode no
# 更改永久保存,客户端修改可以通过这种方式直接改配置文件,无需手动修改
[root@node1 ~]#redis-cli CONFIG REWRITE
# 10.0.0.41:6379任意集群一台机器 46是单节点机器
#只使用cluster-copy,则要导入集群中的key不能存在
#如果集群中已有同样的key,如果需要替换,可以cluster-copy和cluster-replace联用,这样集群中的key就会被替换为外部数据
[root@node1 ~]#redis-cli --cluster import 10.0.0.41:6379 --cluster-from 10.0.0.46:6379 --cluster-copy --cluster-replace
Migrating k1707068 to 10.0.0.42:6379: OK
Migrating k3778193 to 10.0.0.42:6379: OK
Migrating k5728478 to 10.0.0.44:6379: OK
Migrating k8826052 to 10.0.0.44:6379: OK
Migrating k9642751 to 10.0.0.44:6379: OK
Migrating k9401937 to 10.0.0.45:6379: OK
Migrating k9849387 to 10.0.0.44:6379: OK
......
# 一共是一千万条数据,三个主节点每个300多万
[root@node1 ~]#redis-cli
127.0.0.1:6379> DBSIZE
(integer) 3333104
如果开启了保护模式,如图所示:
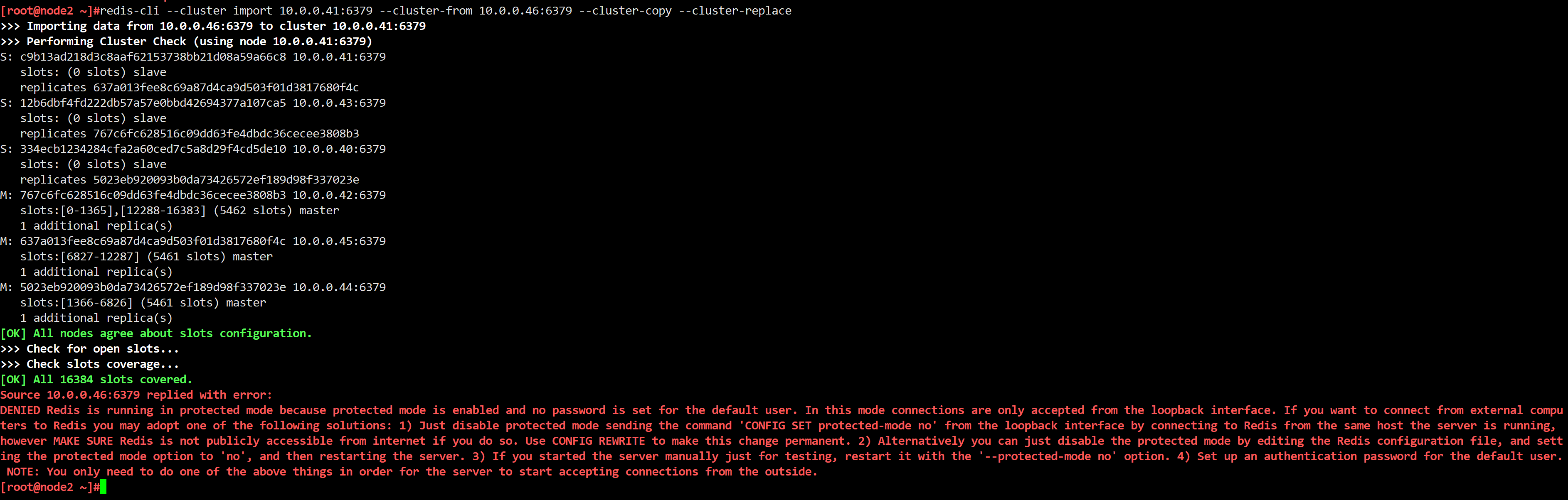
源 10.0.0.46:6379 回应错误:
拒绝 Redis 在受保护模式下运行,因为已启用受保护模式,且未为默认用户设置密码。在此模式下,只接受来自环回接口的连接。如果想从外部电脑连接到 Redis,可以采用以下解决方案之一: 1) 从环回接口发送 “CONFIG SET protected-mode no ”命令,禁用保护模式。使用 CONFIG REWRITE 将此更改永久保存。2) 或者,你也可以编辑 Redis 配置文件,将保护模式选项设为 “否”,然后重启服务器,禁用保护模式。3) 如果只是为了测试而手动启动服务器,请使用“--protected-mode no ”选项重启服务器。4) 为默认用户设置验证密码。注意:只需执行上述操作之一,服务器即可开始接受来自外部的连接。如果那台单节点开启了cluster模式,如图所示:
[root@Rocky9 data]# ps aux | grep redis
redis 1071 3.6 70.4 1161192 670360 ? Ssl 13:25 0:11 /apps/redis/bin/redis-server 0.0.0.0:6379 [cluster]
root 1144 0.0 0.2 6408 2048 pts/0 S+ 13:30 0:00 grep --color=auto redis
[root@Rocky9 data]#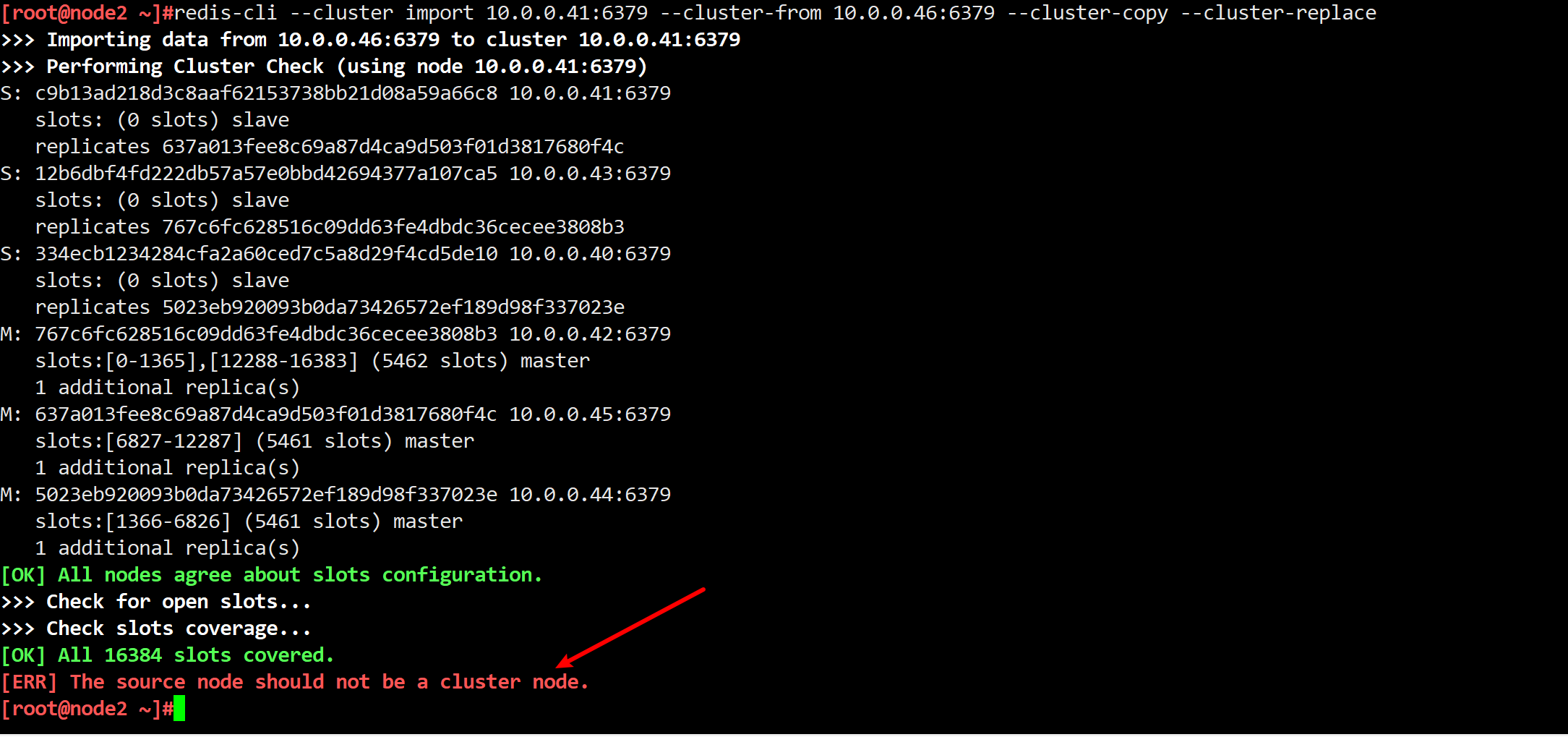
0 Comments